8 min to read
9012年了,你还没做过问答和阅读理解?
Intro to Reading Comprehension and Text-based Question Answering

目前对于问答的研究,主要在研究用事实就能回答的、答案简短的问题(factoid question).
比如中国的货币是什么?人民币.
比如Musée de l’Orangerie在法国的哪里?巴黎.
比如Jean Fragonard是什么风格的画家? 洛可可.
本文也是聚焦在这种类型的问答上面.
目前三种套路思路教电脑回答问题:
- 信息检索+阅读理解(Text-based/TBQA)
- 利用知识图谱(Knowledge-based/KBQA)
- 混合工业风(Hybrid)
本文由于篇幅有限, 先看第一种: 基于信息检索和阅读理解模型的问答.
基于信息检索的问答系统
(IR-based Question Answering)
需要一堆文本里找到一小段话、几个词(span)来回答用户的问题 .
基本框架如下:
从用户提出的问题出发(Question Processing), 使用信息检索系统找到相关的文本和段落(Document and Passage Retrieval),然后使用深度学习的阅读理解模型从一堆段落中截取(Answer Extraction)能回答问题的文段(span of text).
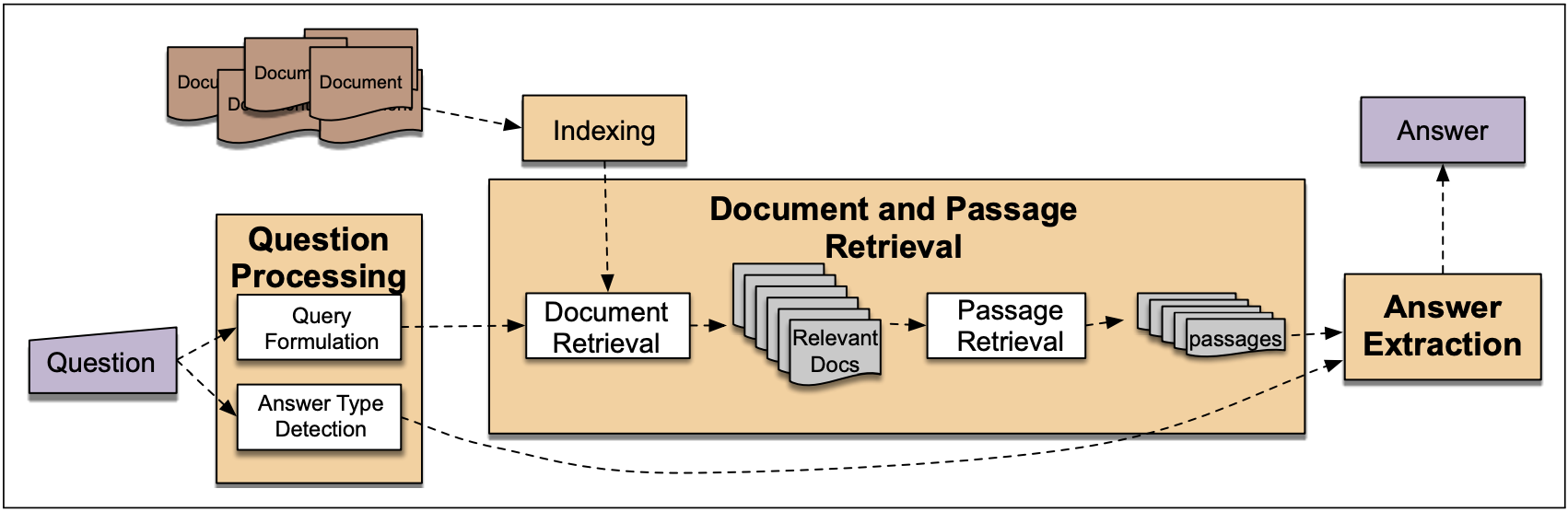
接下来将分为3个步骤逐个解说
最后将聚焦到如何使用深度学习模型做答案抽取,aka如何做阅读理解任务.
对提问的处理
(Question Processing)
要将提问转化为信息检索系统能使用的查询条件,就必须从问题中抽取关键字.
有些系统还会抽取答案的类型(answer type),比如应该回答人、地点、还是对时间的描述?
抽取替换位置(focus), 也就是提问中最有可能被答案替换的位置,比如“哪里”、“什么”.
(1) Query Formulation
对原始问题做处理,有时候会使得后面的信息检索步骤更容易.
如果检索库是整个网络的话,不担心文本不够,可以直接使用原始问题.
如果检索库的文本比较少,比如是公司内部的文本或者维基百科的文章,那么为了增加找到相关文本的概率,往往会通过重写问题(query reformulation)把问题变成陈述句,或者将提问展开成很多种不同的表达形式,希望其中一种能匹配到检索库中的相关文本.
- query reformulation
例子:where was iphone 11 released -> 重写成陈述句-> iphone 11 was released in
注意这些重写虽然是自动的,但是规则都是手写的…
(2) Answer Type Detection
好处是如果我们能知道答案的类型,就可以在检索时跳过没提及答案那一类实体的句子.
比如提问哈利·波特的母亲叫什么名字的答案类型是人名.
标签设置
答案的类型可以直接使用命名实体识别中的类别:PERSON, LOCATION, ORGANIZATION,…
也可以使用带有树结构的answer type taxonomy
以下是一个人工设计的answer type taxonomy, 当然它也可以自动生成
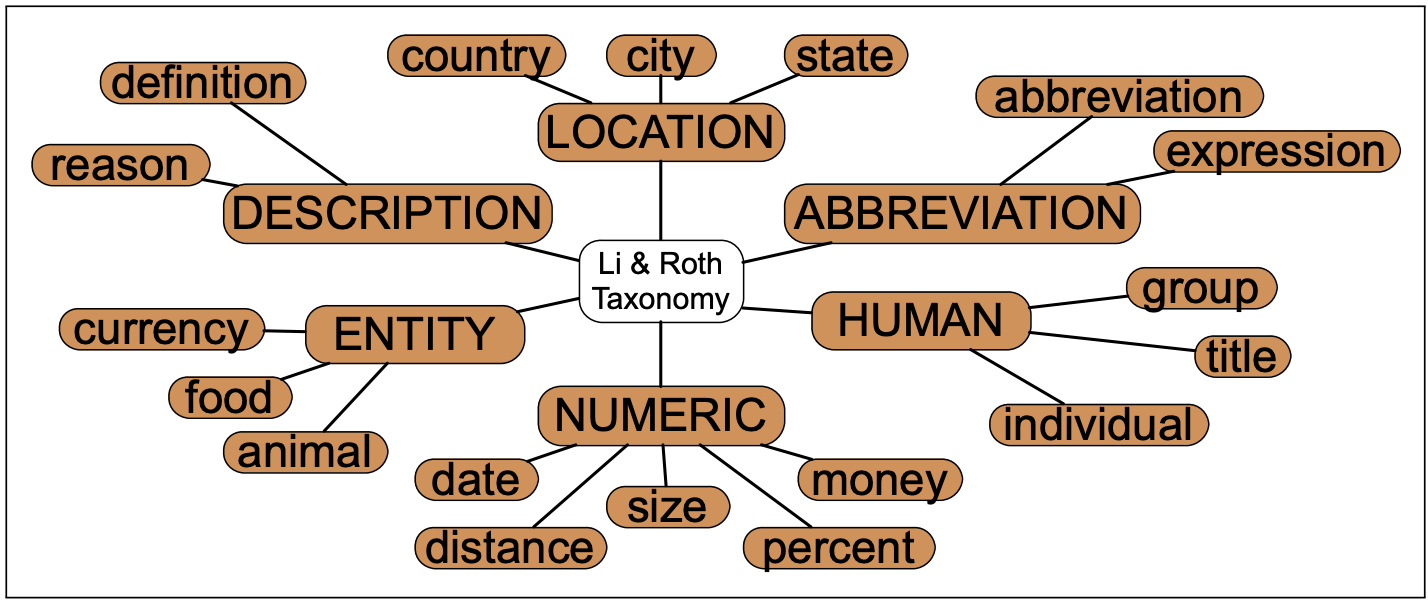
模型
现代一般使用有监督训练提问分类器,使用带有答案类型标签的数据集进行训练.
可以是依赖特征的分类器,也可以是完全依靠神经网络的分类器.
github项目: Keras示例, Torch示例
数据集
- BQuLD
1216个问题,及其答案. 问题的繁体中文与英文翻译都有. 包含了答案的类别. - TREC
包含了1999年-2004年的6个数据集, 包含了答案的类别. - Upenn 实验数据
1000-5500个英文问题, 包含了答案的类别. - Yahoo lab数据集
- L5 - Yahoo! Answers Manner Questions 142627个问题及其答案,还有问题的分类
- L6 - Yahoo! Answers Comprehensive Questions and Answers 4483032个问题及其答案,还有问题的分类
常用的特征
- 提问句子中词语以及词语的词嵌入向量;
- 每个词的part-of-speech标签;
- 句子中的识别出的命名实体(named entities);
- 某些关键提示词(answer type word/question headword)的出现与否,比如疑问词后面的词组.
- What is the state flower of California?
- 哪个城市最适合秋天去?
文本检索
(Document and Passage Retrieval)
从全部文本里选出备选文本和文本中的备选语段.
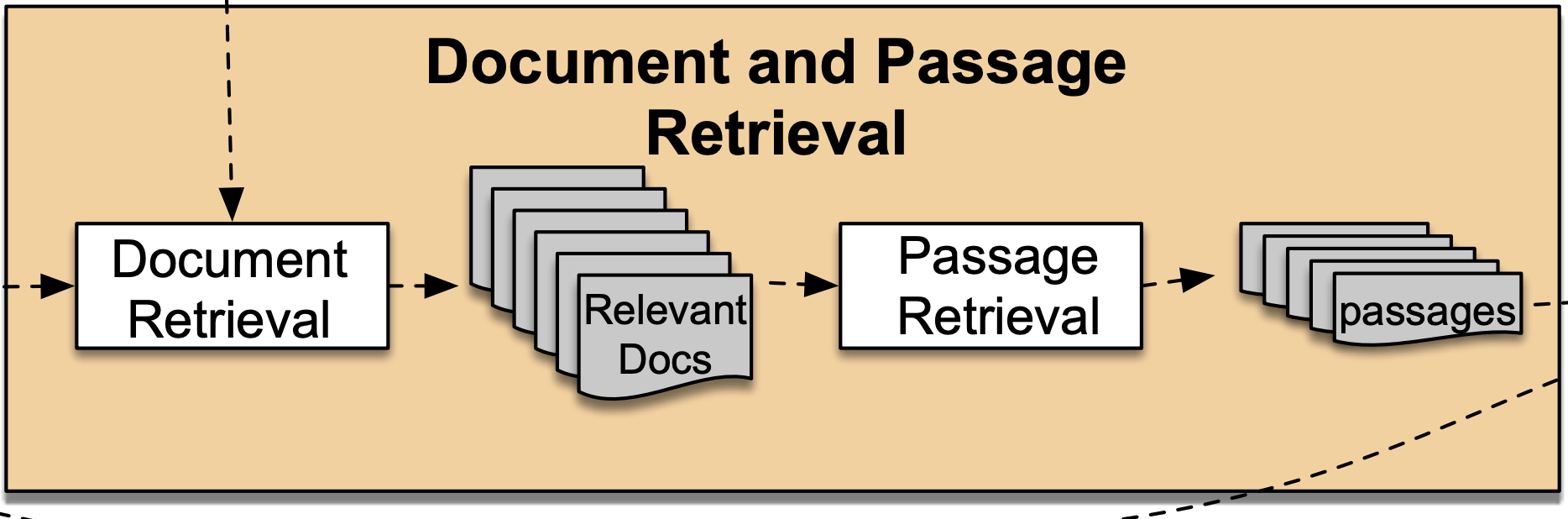
将提问中抽取出的信息输入信息检索系统.
同时把所有备选的文本输入系统,让系统按照相关性对文本排序. 将最相关的N个文本取出. 至此Document Retrieval就做完了.
然后将这N个文本切分成段落、句子、甚至语段, 进一步筛选可能的答案,
最后输出备选语段,Passage Retrieval就做完了.
如何筛选语段
- 对语段做命名实体识别
得到每个语段包含的实体以及类别, 结合提问中利用Answer Type Classification抽取的答案类别,对语段进行筛选. - 训练网络对语段与提问的相关度进一步打分
特征可以包括: 比如提问的答案应该是一个地名,将语段中地名类实体的个数、
提示关键词的个数、所在文本的排名、与提问重合的N-gram个数等等. - 当成阅读理解任务做
比如来2018年的AllenAI的BiDAF模型
由于我找到了写得很清晰的关于这个模型的中文笔记, 这边就不再展开说了.
它使用了改良的注意力机制,预测文本中的每个位置作为回答的开始位置与结束位置的概率.属于有监督学习.
损失函数利用了模型对正确答案的开始位置yi1与结束位置yi2的概率预测:
\(L(\theta) = -\frac{1}{N}\sum_{i}^{N}[ log(p_{y_{i}^{1}}^{1} + log(p_{y_{i}^{2}}^{2})]\)
答案抽取
(Answer Extraction)
任务是从一句话或者一个段落里面找到最能回答提问的语段.
常转化为语段分类任务做: 给一个语段, 决定它里面是否包含提问的答案.
e.g. 哪家公司是湾区出了名的血汗工厂?
亚马逊尝试用各种实验性管理方式逼出员工的潜力,但部分现任和离职员工抱怨公司一些……
旧模型们
- 基于规则(Pattern Matching Parser)
根据每种不同的答案类型,设计常见的pattern,然后抽取固定位置的语段.
e.g. 答案是生日日期
Pattern: [QP] was born on [AP]
这个模型的一个明显问题是模型可复制性很差,换了个答案类型又要重新设计pattern了 - 使用训练好的命名实体识别模型(Named Entity Tagger)
e.g. 你知道提问的答案会是一个地点,就用命名实体识别模型把文本中包含地点实体的语段都找出来.
这个模型的一个明显问题是不能解决答案类型与命名实体类别不同的提问,比如定义类提问. - 基于特征的分类(Feature-based Classifier)
从备选语段中得到以下特征: 是否出现了属于答案类别的实体; 与提问关键字的重合词数;是否包含在提问中没有的新词;语段是否紧跟逗号句号问号感叹号;语段是否是提问中的词的同位语等. - 词组拼贴 (N-gram tiling)
从文本中生成unigram, bigram, trigram. 给N-gram们按照出现频率,有多接近答案的类型打分.
把用词重复N-gram融合为一个更长的语段,分数叠加.
不断地整合,同时把低分的语段去掉,直到没有可以整合的语段了,就输出最高分的语段作为答案.
贪心的算法会先从高分的语段开始tile.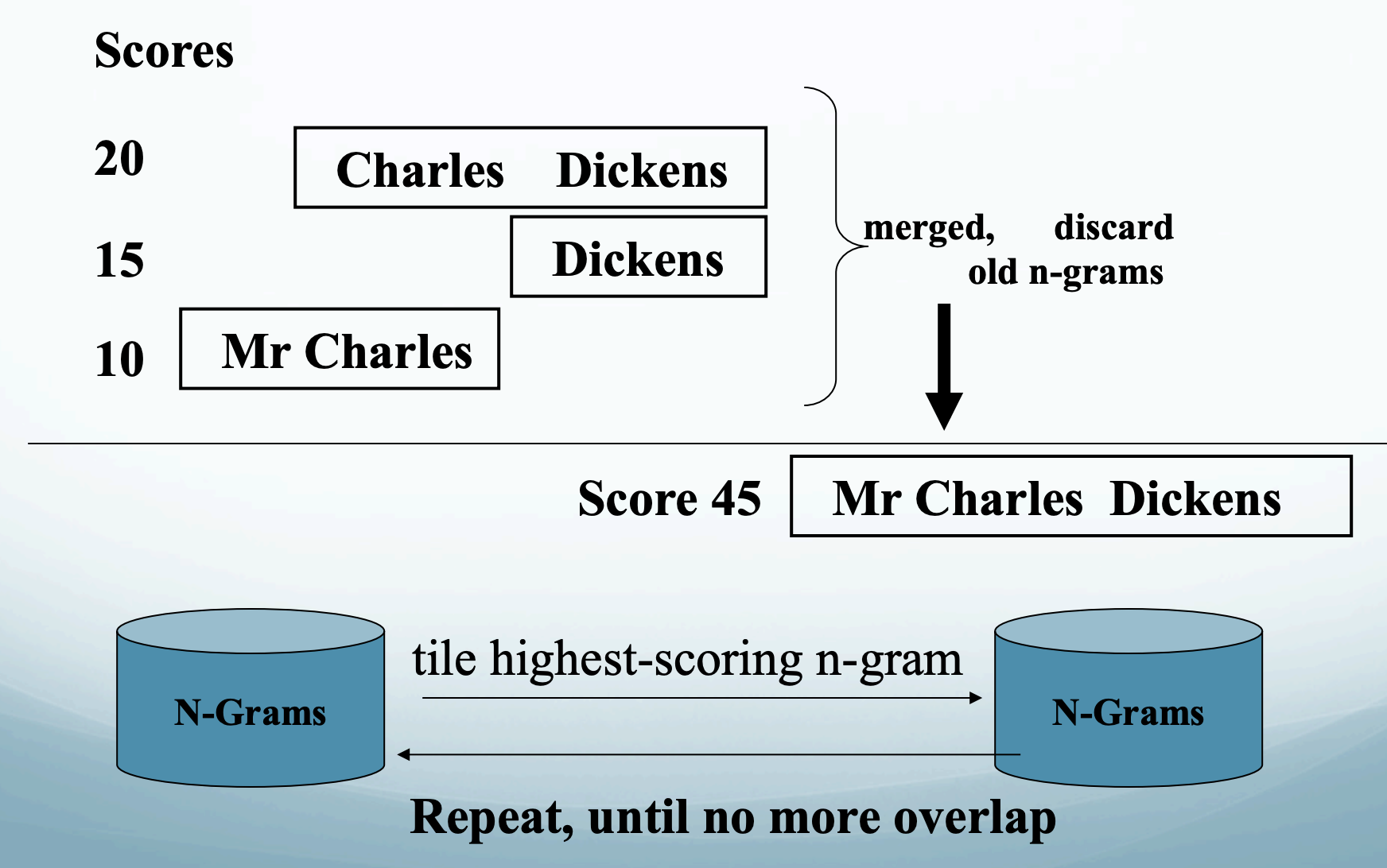 在网络搜索中使用,因为网上重复的文本很多,可以融合很多次.
在网络搜索中使用,因为网上重复的文本很多,可以融合很多次.
现代方法使用神经网络从文本中抽取能作为提问的答案的语段, 常被转化为阅读理解任务.
阅读理解
一种NLP任务. 使用神经网络而不是手写特征的分类器,在一堆文本中找到能回答问题的语段.
我们来看看这三年来影响这个领域的大事件,黑色为数据集,蓝色为模型
 图片来自论文
图片来自论文
阅读理解模型不仅能用来评价一个模型对文本的理解程度,还可以作为问答系统中的阅读器(reader) .
神经阅读理解(Neural Reading Comprehension)模型的出发点: 提问和答案是语义上相似的两个文本.
本部分包括:
数据集
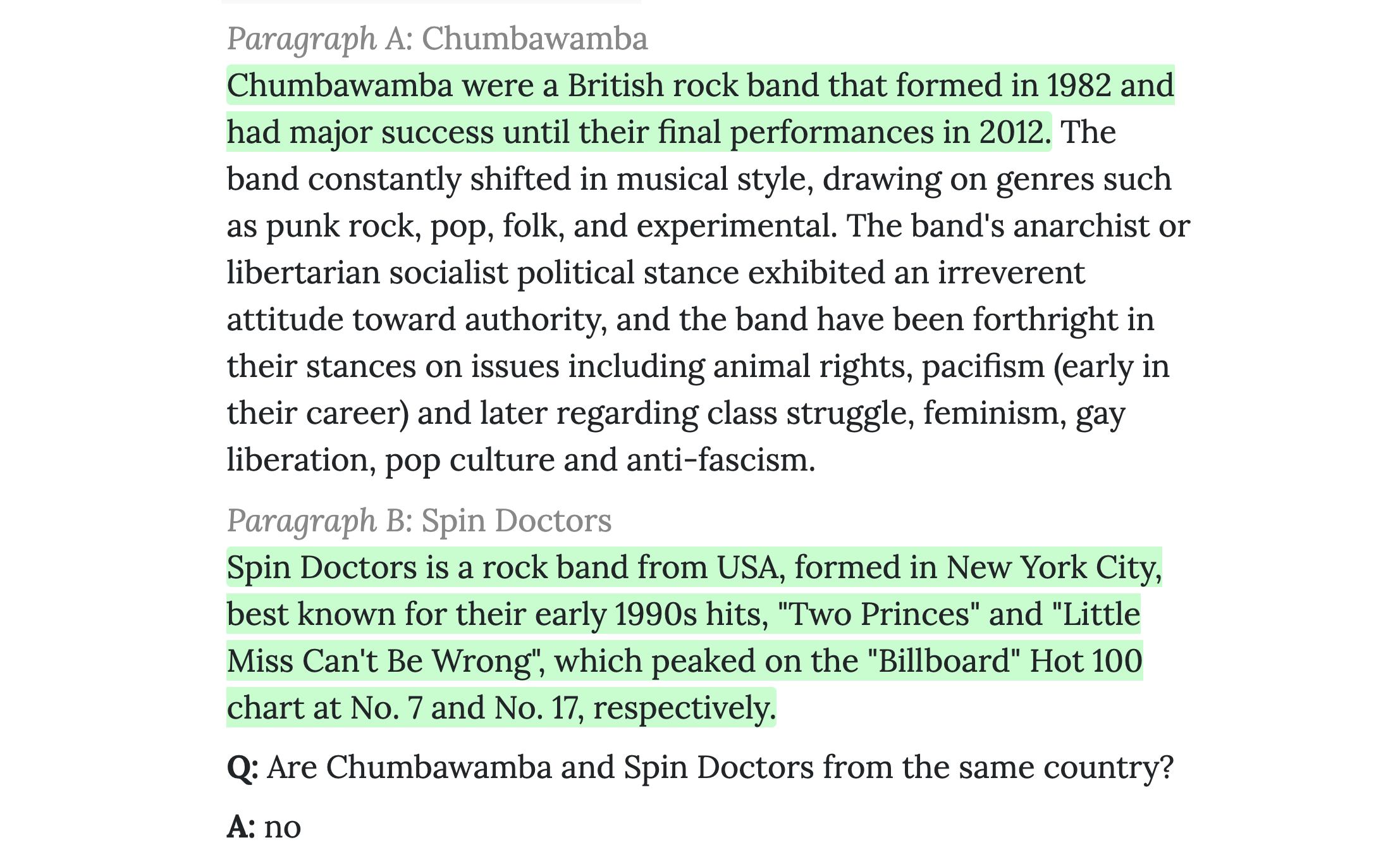
HotpotQA 火锅问答数据集
名字很接地气的大规模多步推理(multi-hop reasoning)问答数据集. 也就是说答案并不是在单一文档的单一句子中,而是需要定位多个信息来源,并基于多个相关信息进行推理才能得到.
一共12万+的英文问题. 通过Amazon Mechanical Turk收集的数据. 向众包工人展示两个维基百科选段,通过一些用户交互设计保证他们可以提问出必须基于两个选段进行多步推理才能得到答案的问题. 还标注了指向答案的支撑证据(supporting facts).
绿色高光部分是答案的支撑证据, 底下是问题和答案:
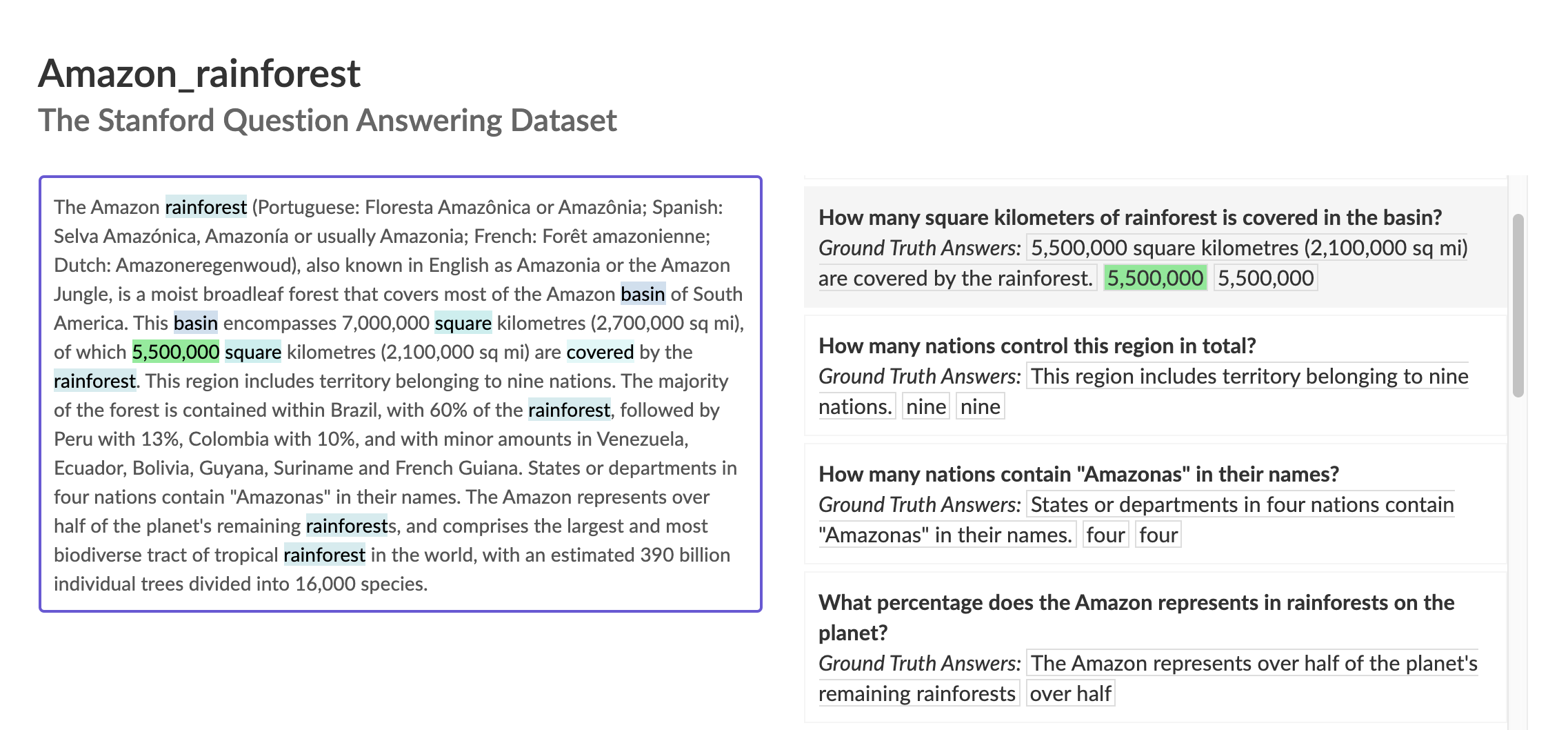
SQuAD 2.0
基于英文维基百科文章内容设计提问,并文中人工抽取语段作为回答,形成的单步推理数据集.
2018年的2.0版本中加入了无法被回答的问题这一个新的类别. 一共15万个问题.(看到数据集也这么积极地迭代版本真是羡慕斯坦福有钱佩服)
左边是关于亚马逊雨林的文章,右边是提问以及黄金答案.
NewsQA
基于DeepMind提供的CNN Dailymail数据集中的新闻文章整理出的10万个问题. 跟SQUAD一样,问题和答案都是人设计人抽取的.包含不可回答的问题.
WikiQA
3047个问题.不包含语段答案,只包含完整句子作为答案.
双向LSTM为核心的模型
输入是一个问题q,有l个词 q1,q2,…,ql
还有一段话p,有m个词 p1,p2,…, pm
跟之前提到的BiDAF模型一样,模型的任务是预测这段话的第i个词 pi 是正确答案的开始位置的概率 pstart(i) 以及 pi 是结束位置的概率yend(i).
以DrQA模型为例看一下模型设计:
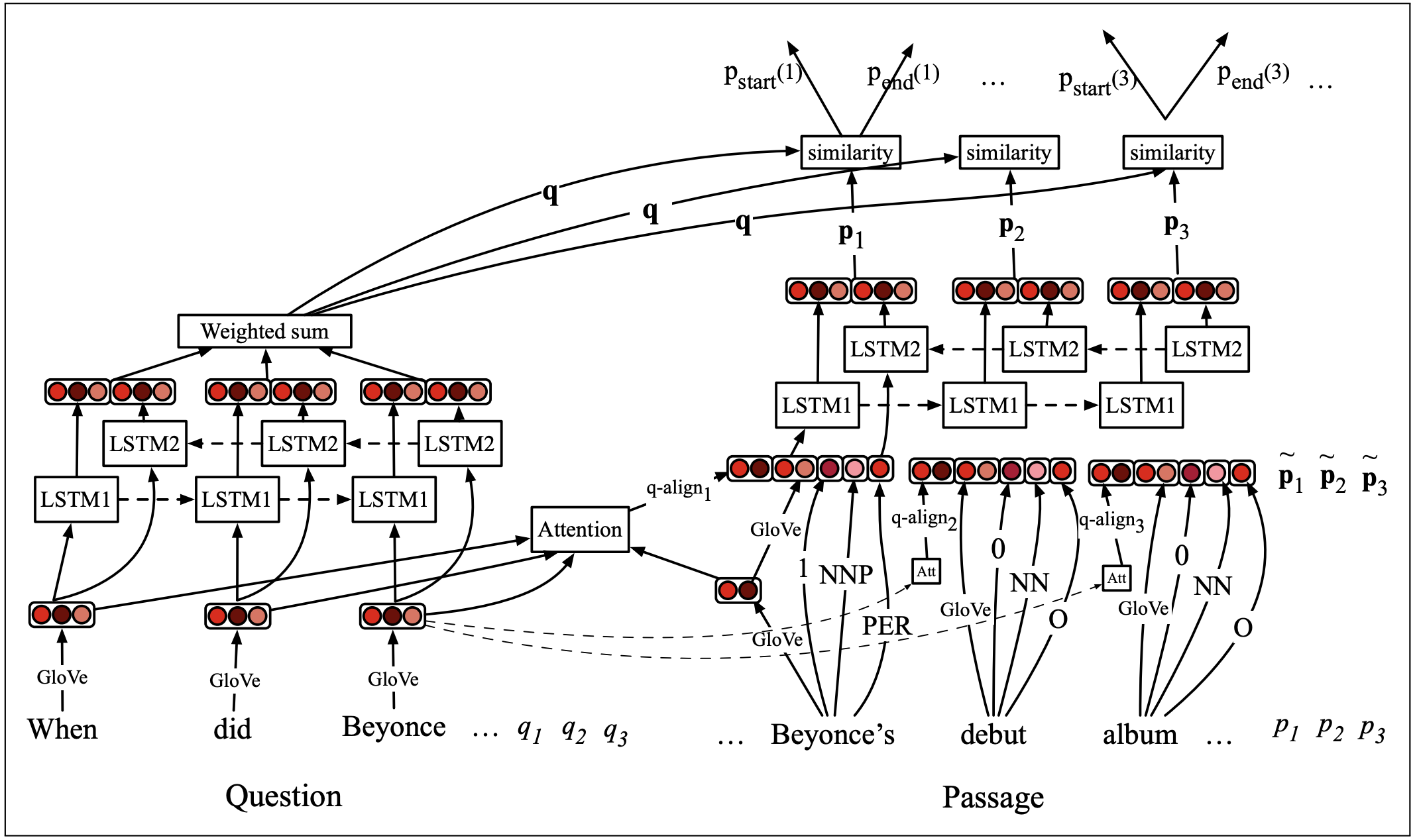 一句话总结就是分别得到问与答的表示向量然后求相似度.
一句话总结就是分别得到问与答的表示向量然后求相似度.
联系回我们之前提到的出发点: 提问和答案是语义相似的两个文本.
讲真这个模型图左半边比右半边好懂好多:
提问部分
先循例得到词嵌入向量,过Bi-LSTM之后加权整合hidden state向量得到提问的向量表示q.
然后跟文本的每个位置的表示向量放在一起求相似度.Totally make sense.
最后使用这个相似度分数决定答案从哪一个位置开始,哪一个位置结束.
- 加权时候的权重哪里算来的?
权重bj是提问中每个词的相关度打分,依靠一个需要被训练的向量w
重点看下Passage部分
\(p = \{p_1, ..., p_m\}\)
经历了什么变成了
\(\tilde{p} = \{\tilde{p}_1, ..., \tilde{p}_m\}\)
需要得到三种不同的向量,然后把它们粘起来:
- 从预训练模型,比如Glove中, 得到的每个词pi的 E(pi)
-
词语的额外特征:用Tagger得到的pi的POS标签; 实体类别标签; pi是否直接在提问中出现过.
- 经过注意力分数加权的相似度向量q-align
用注意力机制算问与答之间的相似度, 好处是能建立问与答之间有关联的词语的关系.- 比如提问中有”内测“一词, 回答中有”游戏“一词. 需要一个矩阵表示qj与pi的相似度
- 用提问中每个词qj的注意力分数ai,j作为加权平均的权重,算一个加权版相似度
(权重ai,j代表了qj与pi的相似度)- 如何计算注意力分数 ai,j?
注意力基本操作:把词嵌入E(pi))和E(qj)通过一个前馈网络,然后乘起来过一个softmax层就得到了ai,j
- 如何计算注意力分数 ai,j?
负责预测功能的部分
训练两个分类器,一个负责开始位置pstart(i),一个负责结尾位置pend(i).
分类器可以就直接点积,不过效果比较好的是加入一层bilinear attention layer.
BERT为核心的模型
效果更更更好的模型.
假设我们的问题有N个词: Token1, Token2, …, TokenN ;
文章有M个词: Token1, Token2, …, TokenM .
把它们前后连接为[CLS] Token1 Token2 … TokenN [SEP] Token1 Token2 … TokenM
输入预训练过的BERT, 拿到文章中每个词对应的词向量Ti’ .
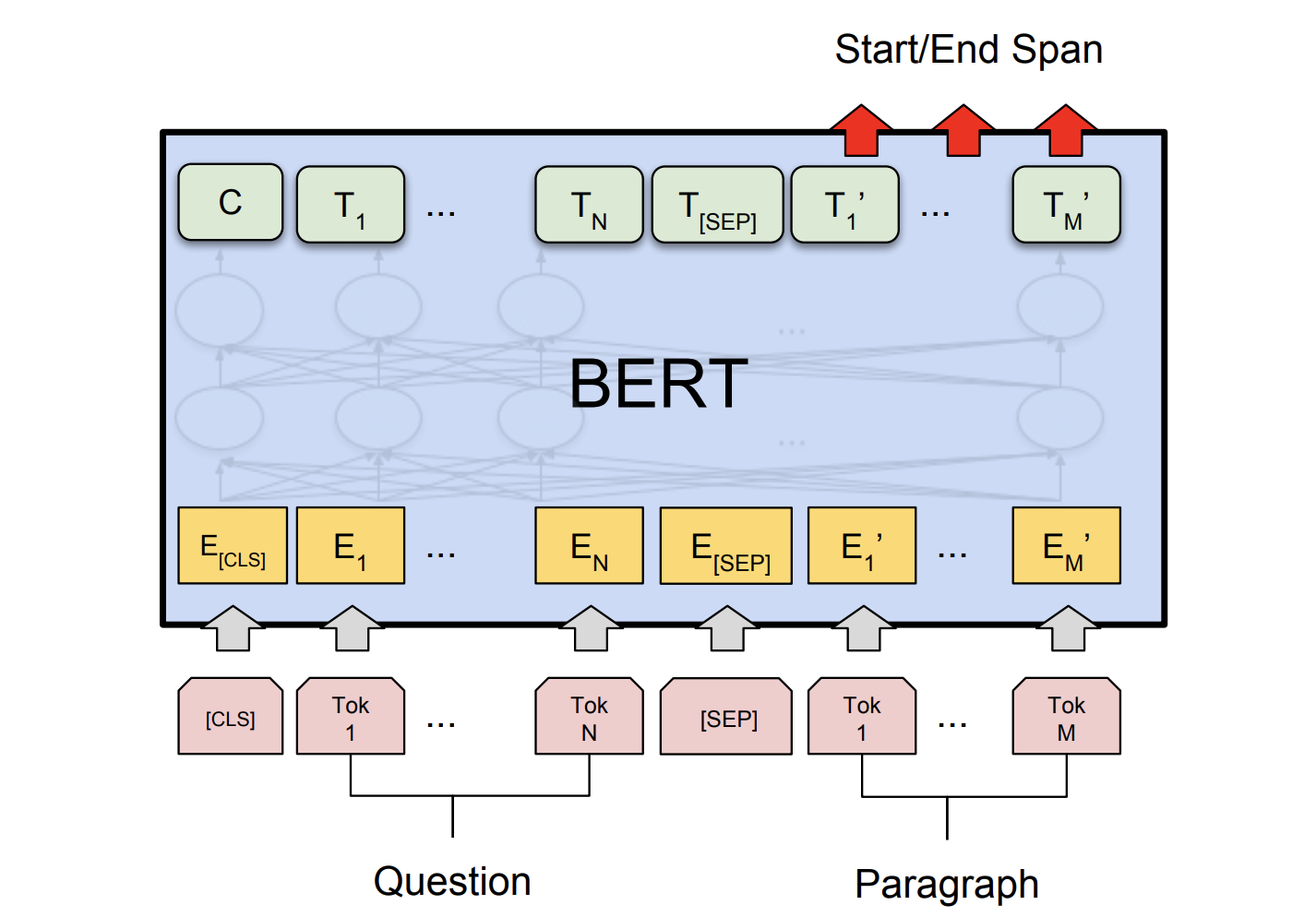 图片来自论文
图片来自论文
加入另外两个向量: 代表答案开始的S和代表答案结束的E.
用S然后E,分别与词嵌入向量Ti’ 求点积再normalize成概率, 就得到了第i个位置的词是答案的第一个词的概率 Pstarti和这个词是答案最后一个词的概率 Pendi
每个从i位置开始,从j位置结束的备选答案SPANi, j的分数= S x Ti + E x Ti
模型会选择分数最高备选语段作为提问的答案.
目标函数是每个黄金答案的开始词和结束词对应的位置被模型给予的log likelihood的和.
做多步推理的图网络模型
不同于传统的问答系统,多文档问答需要模型从数个文档中协同地寻找问题的答案,要求模型有很高的多步推理(multi-hop reasoning)能力.
这两年拿图注意力模型去做效果不错. 比如图注意力模型(graph attention network/GAT)TF代码, 图循环网络(graph recurrent network/GRN)TF代码.
动态融合图网络(DFGN)结合了图网络和BERT,我们就拿它来学习一下.
论文
pyTorch代码
模型由5个部分组成:
负责筛选段落的分类器(淡紫色),负责提取实体并构建图的模块(橘色),负责把问答转化为表示向量的编码器(黄色), 负责多步推理的混合模块(蓝色),负责预测支撑证据和答案的起始位置的分类器(绿色).
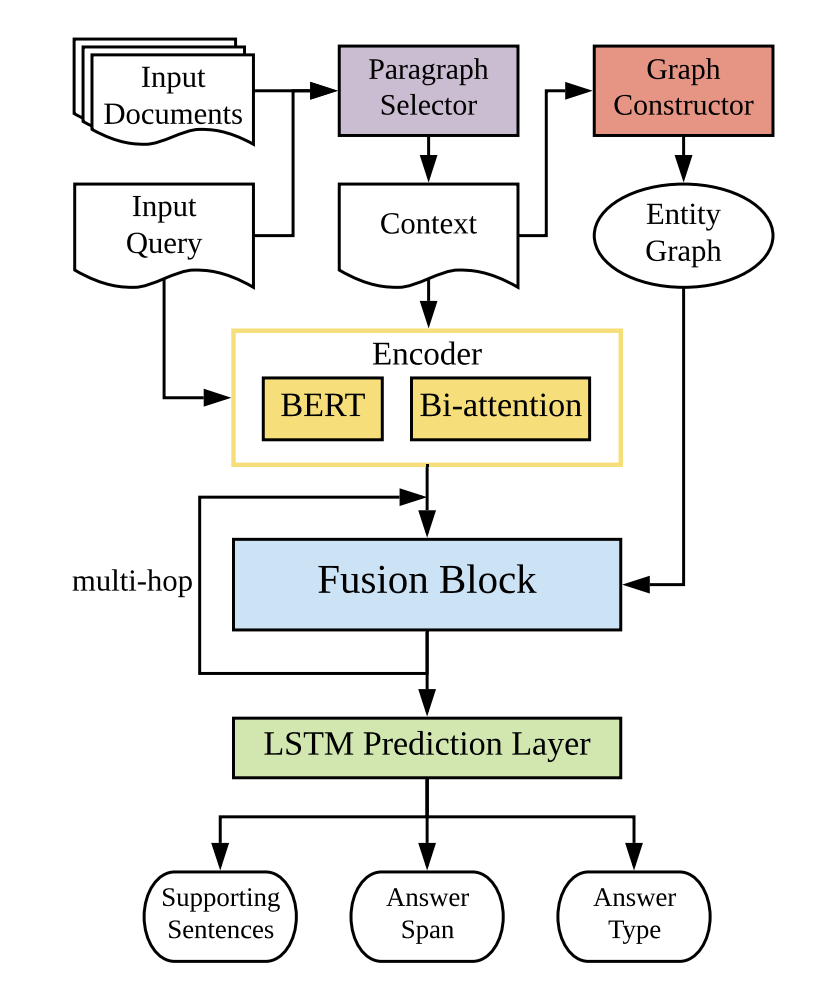
筛选段落的分类器
不是全部段落都包含与答案相关的支撑证据(supporting facts),首先用一个基于BERT的二元文本分类器把不相关的段落去掉. 通过的段落会被粘起来变成背景知识 C .
构建实体图
使用了Stanford corenlp toolkit从 C 中提取 N 个命名实体.
那么实体之间的连接如何建立?
- C 中同一句话里出现的实体之间连起来
- 对应到C 中同一个mention的实体之间连起来
- 从每个段落的标题中找出一个核心实体,将核心实体 与同段落里的其他实体连起来
编码成向量
将提问 Q 与筛选后得到的 C 前后粘在一起,送进预训练过的BERT. 出来之后再送进一个bi-attention层,加强问答之间的关系.
假设 Q 有L个词,C 有M个词,得到提问的表示向量(L x d2)和背景知识的表示向量(M x d2).
多步推理
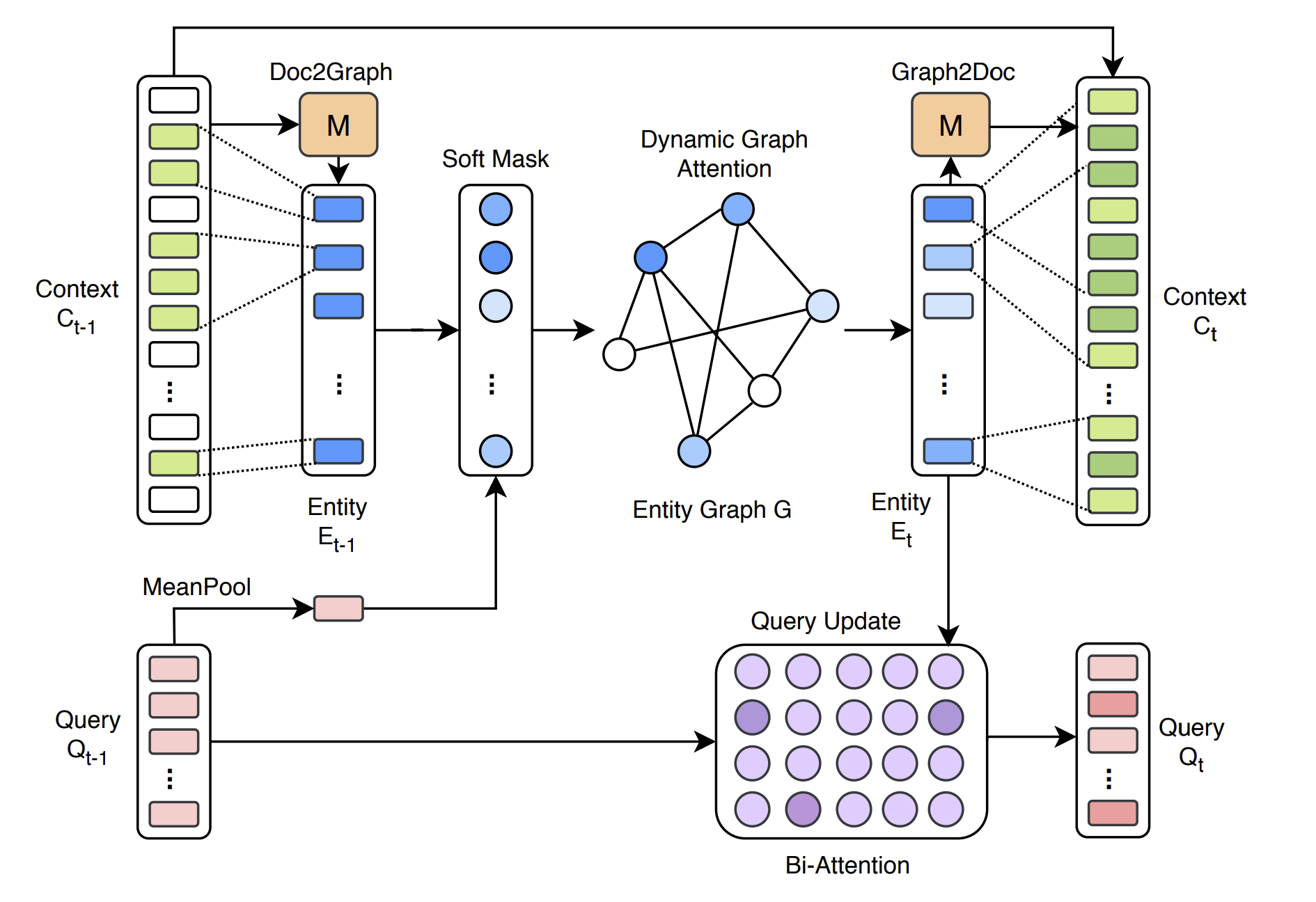
-
Doc2Graph
先用C中的所有词找到对应的实体E
怎么找到?使用矩阵M -
图上搜索
用注意力网络和经过MeanPool的提问向量计算soft mask
用soft mask来代表实体与提问Q之间的相关度, 选出起始的实体节点
使用类似GAT的模型计算两节点间的注意力分数alpha, 出发节点的向量会被更新为邻节点信息的加权平均
每一次推理新访问到的节点会成为下一次推理的起始节点,通过这样的设计把信息一步步扩散到邻近节点去
同时使用bi-attention网络更新提问的表示向量
Q(t) = Bi-Attention(Q(t−1), E(t)) -
Graph2Doc
将相关实体E用M对应回C中的词
因为最后的预测是基于词语的.
预测
用四个结构一样的LSTM叠在一起预测下面四样东西:
- 支撑答案的句子
- 答案开始词的位置
- 答案结束词的位置
- 答案的类型
损失函数是四个分类器自己的交叉熵的加权平均:
L = Lstart + Lend + λsLsupport + λtLtype
总结
本文完完整整地介绍了基于信息检索和阅读理解模型的问答系统可以怎么做, 从对提问的预处理,到使用文本检索筛选段落,再到使用不同的模型抽取答案语段.
常将答案抽取化为阅读理解任务去做.
其中神经阅读理解模型我们介绍了三种方向,双向LSTM为核心的模型,BERT为核心的模型,图网络模型.
开源项目或论文的代码实现,数据集的下载链接都已经在文中链接里啦.
Reference
- Speech and Language Processing - Question Answering
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Bi-Directional Attention Flow for Machine Comprehension
- 徐阿衡同学的笔记 - Bi-Directional Attention Flow for Machine Comprehension
- 陈大神毕业论文 Neural Reading Comprehension and Beyond
- Graph Attention networks
- A Graph-to-Sequence Model for AMR-to-Text Generation
- Dynamically Fused Graph Network for Multi-hop Reasoning
- Know What You Don’t Know: Unanswerable Questions for SQuAD
- HOTPOTQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
- NewsQA: A Machine Comprehension Dataset
- WikiQA: A Challenge Dataset for Open-Domain Question Answering
- University of Washington - LING 573 slides
- NLP Progress - Question answering


Comments