5 min to read
问答也可以结合知识图谱
Knowledge-based Question Answering and How to Evaluate QA models

上一篇介绍了如何利用Information Retrieval和阅读理解模型来做单步乃至多步推理问答系统.
本文介绍另两种问答系统的思路:
以及如何评价问答系统.
基于知识图谱的问答
将提问文本转化为对数据库的查询语句,然后通过查询已有数据库得到问题的答案.
其中语义解析器(semantic parser)负责将提问文本转化为按固定逻辑表达的查询语句, 而数据库可以是真正的关系型数据库,也可以是一堆三元组(RDF triples)1.
以三元组为例,问答任务可以定义为根据提问找到对应的三元组,并返回提问所需的三元组成员.
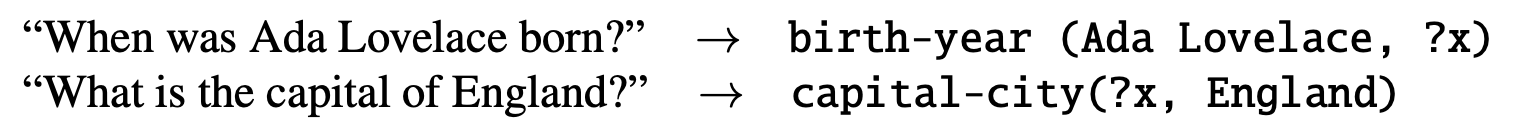
基于规则的方案
很常见的提问可以直接写规则找到三元组.
比如问某个实体的生日日期,可以先正则表达式找到提问中的when和born,然后跑个命名实体识别得到实体名.
有监督模型
少数情况中我们有标注数据.
- 对于每个训练集的提问, 都标注了它的逻辑表达式:
| Question | Logical form |
| 加州的首府在哪里 | 首府在(加州, ?x) |
模型会在训练中总结出提问的套路,形成对一类提问的解析规则(parsing rule).
- e.g. 训练集中有很多对生日日期的提问:
When was Tom Hiddleston born -> birth-year(Tom Hiddleston, ?x)
When was Christopher Manning born -> birth-year(Christopher Manning, ?x)
…
那么训练后的模型会总结出如下解析规则
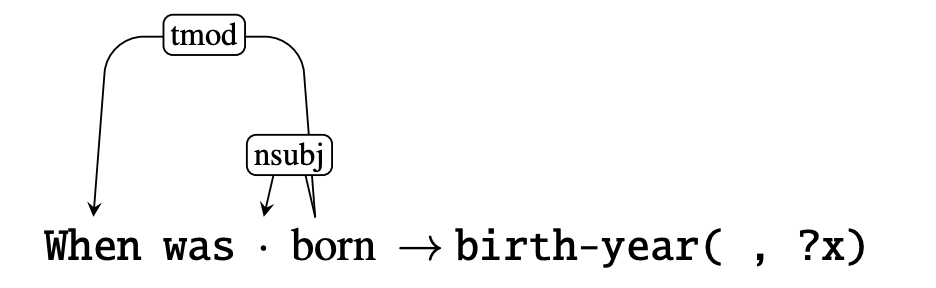
也有论文证明过即使是较复杂的逻辑关系也可以这么学出来.
半监督/无监督模型
问题是大多数情况下我们都没有专门的标注数据.也没有数据库.
所以模型一般都依赖于网络上的文本会有重复(textual redundancy).
步骤
- 先用开放信息抽取(Open Information Extraction) 来抽取网络文本中的三元组,形成一个庞大的知识库.
英文抽取器有REVERB和它的升级版OpenIE 5.- “1732”这种对时间描述 可以用SUTime标准化
- 将提问文本转化为标准化的查询语句
- 实体转化为数据库中的某个概念
“Fragonard”用Entity Linking2对应到维基百科的一页 - 实体间的词组转化为数据库中的某种关系
目前已经有人生成了一系列能对应到Freebase relation的惯用词组列表.对应到country.capital关系的惯用词组: capital of, capital city of, become capital of, capitol of, national capital of, official capital of, ..., federal capital of, beautiful capital city of如果提问文本中的谓语词组能与列表中的词组对应,那么就对应上了Freebase的关系.
- 或者把提问按写好的模板转化为查询语句
| - Question Type - | ——— Pattern ——– | —- Query —- |
| Question (1-Arg.) | how big is e population | population(?, e) |
- 实体转化为数据库中的某个概念
- 同义提问聚类
利用[WikiAnswers语料库]训练同义句模型,将同义不同表达的提问对应到同一个查询语句上.
可以参考PARALEX模型- 像下面这堆提问应该被聚类到同一个群里, 然后通过查询找到同一个三元组
authored(milne, winnie-the-pooh)来回答

- 像下面这堆提问应该被聚类到同一个群里, 然后通过查询找到同一个三元组
结合TBQA和KBQA的工业QA
在实际工业应用中,我们其实不拘泥于达到目的的方式, whatever works.
我们可以从Text-based模型和Knowledge-based模型中分别得到大量的备选答案,
为备选答案设计支撑他们是答案的特征,然后通过分类器给他们打分,选择分数最高的备选答案作为最后输出.
注意分类器的输入将非常不平衡,因为大部分都是错误答案,只有一小部分是正确答案. 这时候常用的处理方式有Instance weighting.
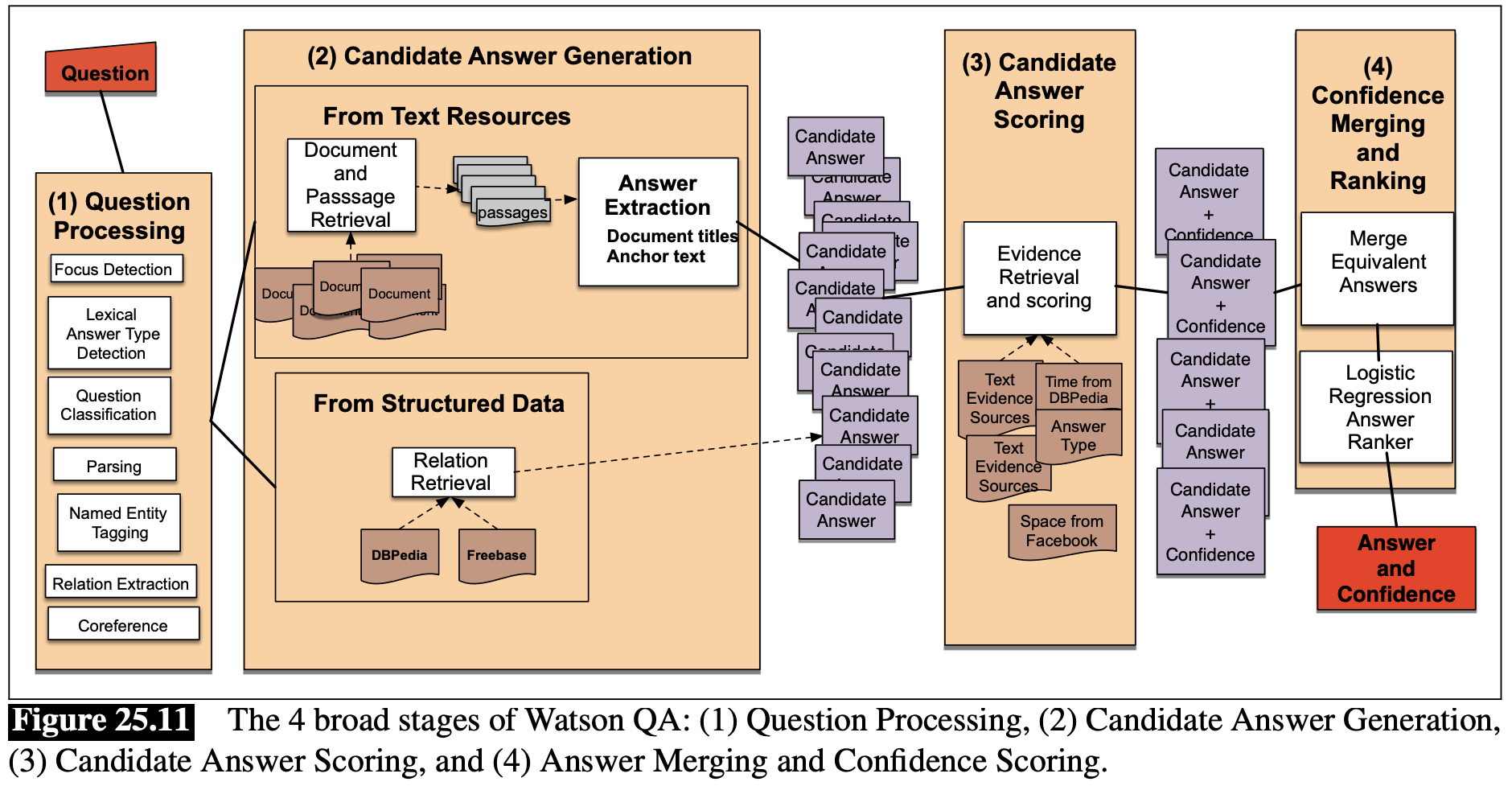
这类的模型可以参考IBM的DeepQA,由于里面太多rule-based的设计,细讲实在没意思,这边就不展开说了.
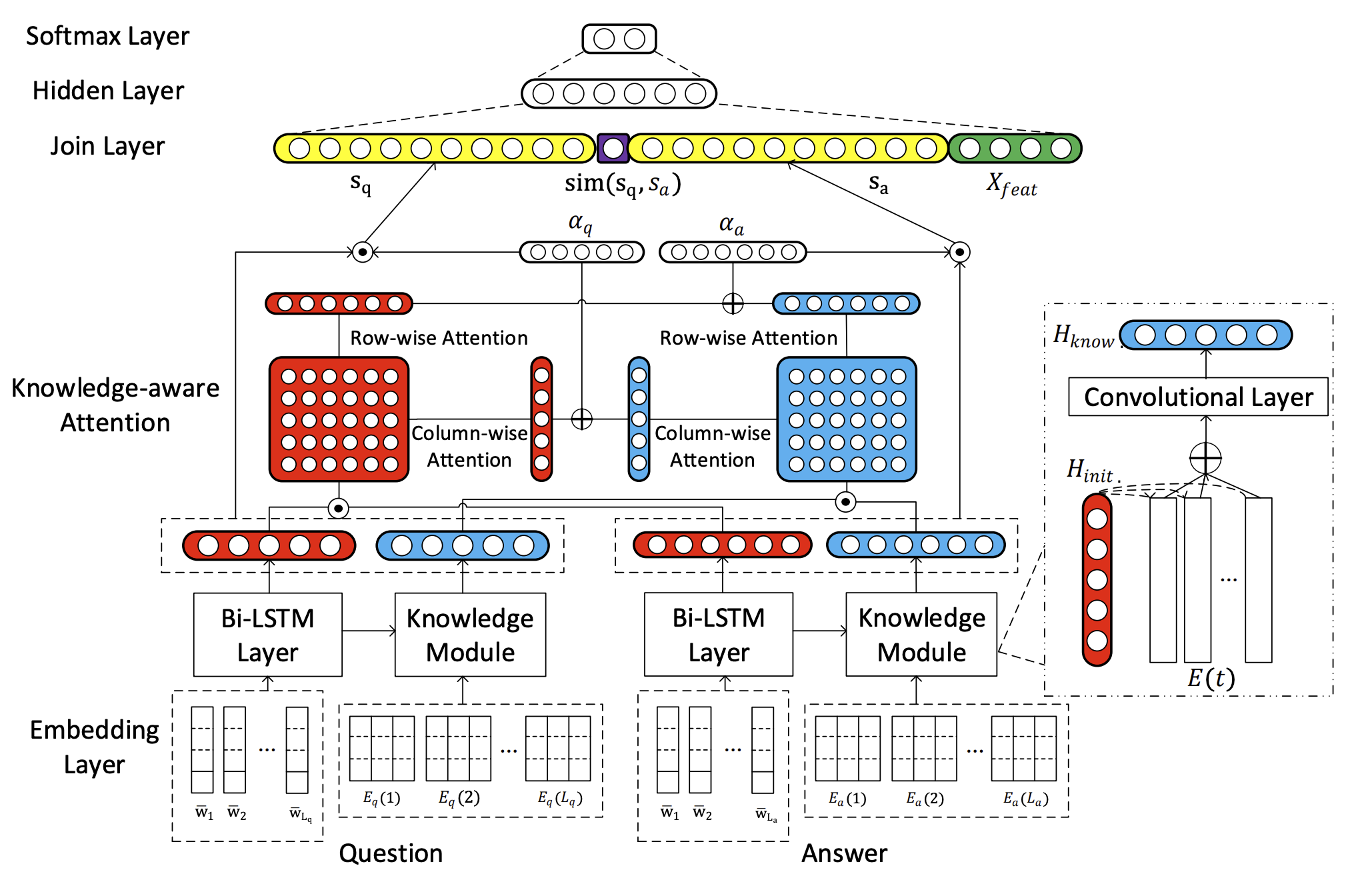
另外一种结合TBQA和KBQA的方式——把外部知识也做成表示向量
具体可以看KABLSTM模型 代码
如何评价问答系统
- 有哪些可以使用的测试集
- 有哪些常用的评价指标
测试集
TriviaQA
9.5万个人工生成的提问-回答对子.共65万条数据, 每条是(提问, 回答, 支撑证据)
平均每个问答对子有6条支撑数据.
RACE
基于中国初高中学生的英语测试
英语老师们从2.8万篇文章中提出10万个问题,数据集对模型的推理能力会有高要求.
NarrativeQA
提问基于长文本.
人工从1572个故事(书/电影脚本、以及它们的人工摘要)中,提取出4.6万个问题及其答案.
QuAC
首先, logo是个小鸭子也太可爱了!
跟SQuAD2.0数据集设定差不多但是包含了一个新的对话相关部分.十万个问答.
AI2 Reading Challenge(ARC)
针对简单使用lexical method的模型的对抗测试集. 7千多个问题.
- e.g. Which property of a mineral can be determined just by looking at it?
(A) luster [√] (B) mass (C) weight (D) hardness - e.g.2 A student riding a bicycle observes that it moves faster on a smooth road than on a rough road. This happens because the smooth road has __
(A) less gravity (B) more gravity (C) less friction [√] (D) more friction
评价指标
Mean Reciprocal Rank(MRR)
衡量模型输出的答案是否正确
\(MRR = \frac{1}{N}\sum_{\substack{i=1{}\\s.t. rank_{i} \neq 0}}^{N} \frac{1}{rank_{i}}\)
要求每个问题有标注好的正确答案,且模型会输出排好序的备选答案.
精髓是找到在模型输出的一堆可能答案中, 第一个正确答案排第几.整个模型的MRR是每个问题MRR的平均.
- e.g. 问题Q1有两个正确答案A1, A2,
模型输出了[A4, A3, A2, A6, A1]这5个答案.
因为第一个正确答案在第3个位置出现, 所以Q1的MRR=1/3.
Exact Match
要求每个问题有标注好的正确答案.
精髓是百分之几的输出答案与问题的正确答案完全重合(忽略标点和量词后)
F1 score
要求每个问题有标注好的正确答案.
将输出答案与正确答案看成两袋词语,算每个问题的F1. 模型的F1是每个问题F1的平均值.
Reference
- Speech and Language Processing - Question Answering
- Paraphrase-Driven Learning for Open Question Answering
- Open IE - AllenAI
- RACE: Large-scale ReAding Comprehension Dataset From Examinations
- TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
- The NarrativeQA Reading Comprehension Challenge
- QuAC : Question Answering in Context
- Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
- Knowledge-aware Attentive Neural Network for Ranking Question Answer Pairs


Comments