4 min to read
图卷积网络是什么鬼
Diving into Graph Convolutional Network

今天我们来看看最广为人知的图神经网络结构——GCN.
P.S. 本文假设读者对CNN有了解,这边就不赘述啦.
本文要点
图卷积网络是什么
一句话,GCN的目的是把只能用图表示的信息,放进CNN里,让模型可以在已有特征的基础上,利用这类节点之间的信息,帮助做决策.
它怎么做到的呢? 就是将图包含的信息编码成表示向量(Node Embedding),然后利用频谱图理论(Spectral Graph Theory)重新设计CNN里的convolution filter,其他都是CNN基本操作.
这一部分将分为以下三点:
什么是图?
一张图由节点(V)和线(E)组成,比如在社交网络里,我和我的朋友们每个人就是一个节点(vertice),我跟每个人之间的关系就是连接两个点的线(edge).
\[\mathcal{G}=(\mathcal{V}, \mathcal{E})\]
首先我们要给模型喂图,就必须把图表示成模型可以接受的形式,比如矩阵、表示向量.
研究如何建模将图表示为节点嵌入向量的工作称为图上表示学习(Representation on Graph).
我们会在第二部分详细展开,目前先假设我们已经得到了图的表示矩阵.
图卷积模型的基本框架
设计一个Filter层,使得它可以: f(X, A) = Z
输入节点们的特征矩阵X和图结构的表示矩阵A,输出一个包含图上关系的特征矩阵Z.
把Filter层叠起来、然后过softmax之类的得到输出,恭喜你有了一个GCN.
只不过具体每个模型Filter层的f函数可能不同.
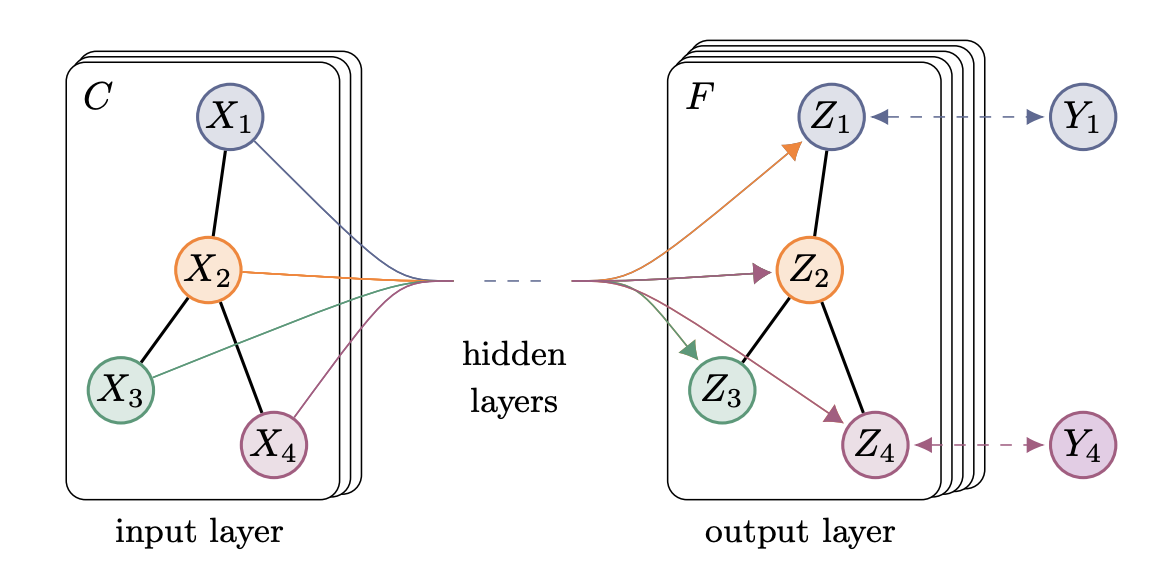 再以社交网络为例:
再以社交网络为例:
假设网络中有N个人,我们每个人有D种特征(性别、年龄、是否刷B站、是否玩微博等等),那么
- 图有N个节点
- 每个人Xi拥有D个特征
- Filter的输入有2个
(1)维度为NxD的特征矩阵X
(2)能表示图上结构的矩阵A(一般是Adjacent Matrix) - Filter的输出是节点级别的特征矩阵Z
假设对每个人输出一个长度为F的特征向量,那输出矩阵Z的维度为NxF
当我们把Filter层叠起来,就有了一个通用的公式:
\[ H^{(l+1)} = f(H^{(l)}, A) \, ,\]
其中第一层时H(0) = X,最后一层时H(L) = Z
注意不同层之间是共享网络连接结构的.
不同GCN类模型的区别就在如何表示图以及f函数的设计上了.
设计图卷积模型的小技巧
- 一般activation是leaky Relu
- A不能直接使用Adjacent Matrix, 因为不包含节点自己与自己有连接的情况. 因此起码要在矩阵A的基础上加上Identity Matrix I,给所有节点加self loop.
- 原生的矩阵A需要标准化,不然跟特征矩阵X乘起来的时候会大幅改变输出的取值范围. 这时候要使用度数矩阵D进行标准化.
选择1: A -> D-1A 相当于对邻近节点们的特征矩阵求平均.
选择2: A -> D-1/2 A D-1/2 对称的标准化, Kipf在ICLR 2017用的这个.
图的表示学习
定义任务
Representation Learning on Graph研究的是如何自动生成任何图的表示向量
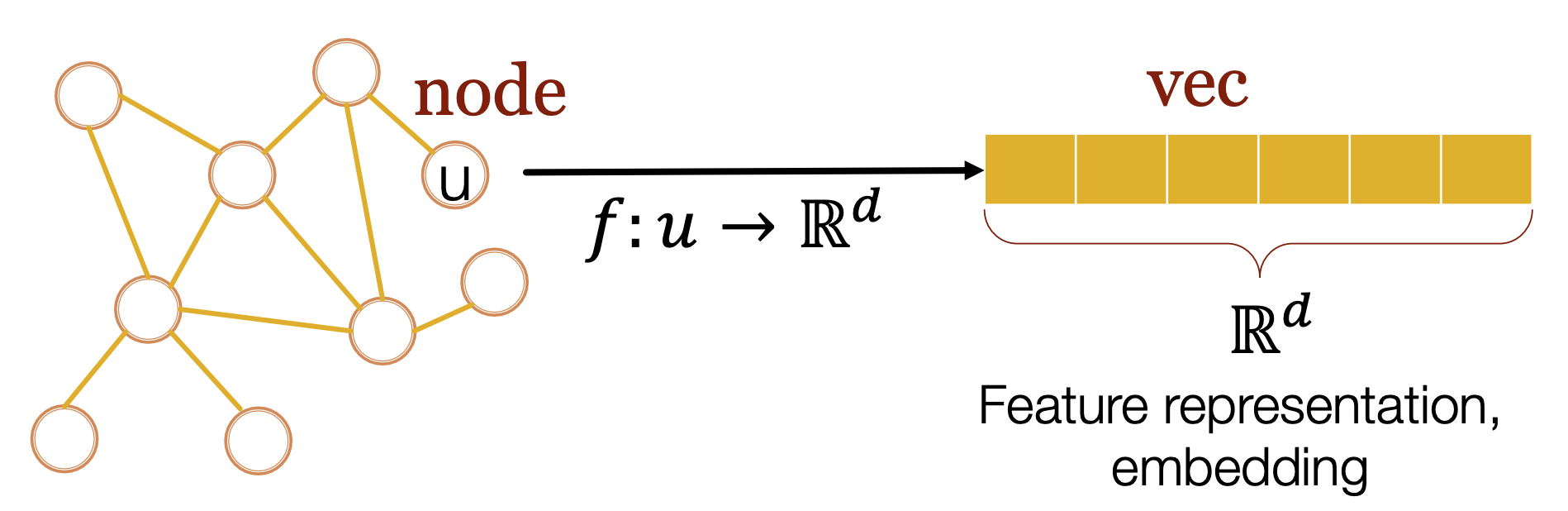
如何将每个节点的信息映射到一个低维空间里面, 并且确保:
在图上邻近的两个点i和j,它们对应的表示向量在映射空间也是相邻的(aka两个向量的点积小).
\[similarity(u_i, u_j) \approx Z^\top_{u_j}Z_{u_i} \]
为什么任务很难?
- The Isomorphism Problem
网络不止二维, 从不同参考节点出发或者按不同的顺序去读取同一个邻近矩阵,得到的网络是不同的. - The Multimodel Problem
介绍几类节点表示模型
首先, node embedding模型有两个组成部件
- 一个描述两个点在图上距离的similarity metrics
- 一个把图转化为向量的编码器模型
Shallow编码器
每个节点对应一个不同的向量,编码器只是一个字典,供查询.
随机游走编码器
训练分为3步:
a. 对图上的每一个节点u,从节点开始跑一些固定长度的随机游走.
b. 对每个节点u, 记录遍历的节点们,放入允许重复记录节点的集合NR(u)中.
c. 用SGD优化器优化目标函数:
\[\mathcal{L}= \sum_{u\in V} \sum_{v\in N_R(u)} -log(P(v|Z_u)) \]
这个目标函数意思是, 对每个节点u路过的每个邻近节点v,模型预测他们同时出现的概率越大, 模型损失越小.
\[ \mathcal{L} = \sum_{u\in V} \sum_{v\in N_R(u)} -log \frac{exp(z_u^T z_v)}{\sum_{n \in V}exp(z_u^T z_n)} \]
- 上面这个P直接算的话 复杂度为V2, 所以实际上分母不会是w.r.t全部node,是会用Negative sampling选固定数量node做标准化.
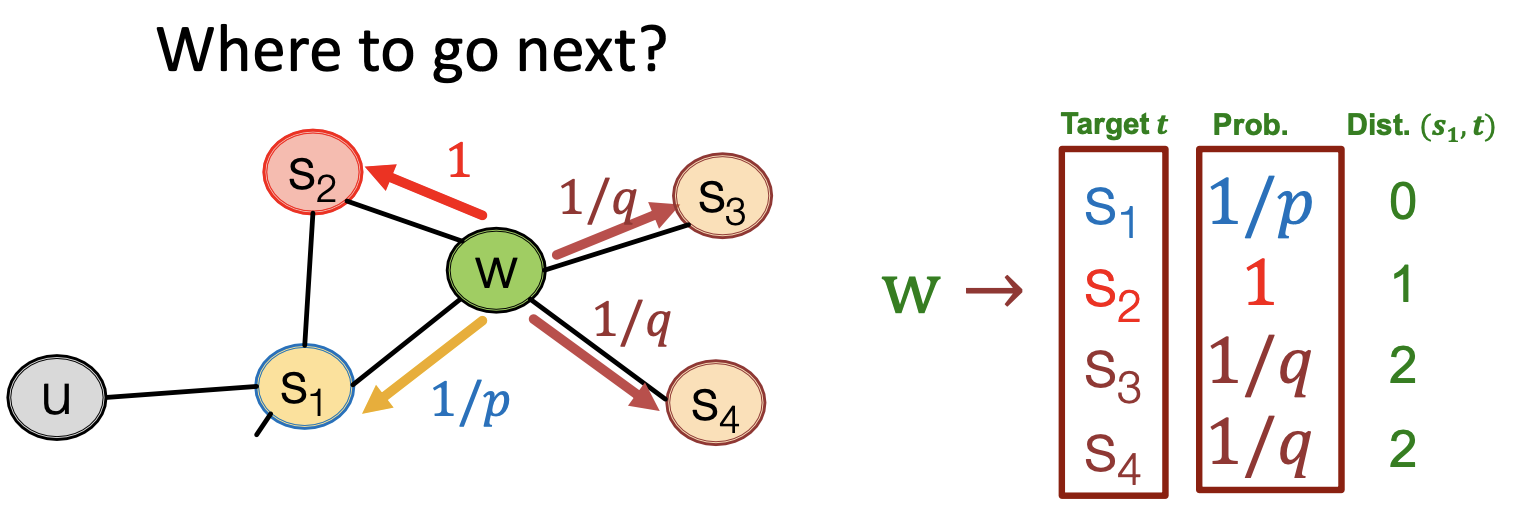
- 不同模型的随机游走规则不同, node2vec是设置了biased walk的(为了在BFS和DFS之间平衡).
p代表回头(缩短与起始节点的距离),q代表往前(加大与起始节点的距离).
定义Similarity
标准很丰富, 两个点很相似如果:
- 它们之间有连接
- 它们有共同邻居
- 它们在网络结构中的位置相似(比如都是社区核心)
- 在网络中随机游走,它们在同一次游走中都被经过的概率很大
如何将图的一部分表示为一个向量(Graph Embedding)
可以把大图里面的子图(subgraph)用一个dummy node表示,然后按照正常节点表示模型去做.
(详细可以看Gated Graph Sequence Neural Network - ICLR 2016)
或者参考Anonymous Walk Embeddings - ICML 2018
现有的图表示模型们
- HOPE (KDD2016)
- SDNE (KDD2016)
- DeepWalk(KDD2014)
- node2vec(KDD2016)
根据斯坦福这篇论文呢,现在表现比较优秀的是清华的SDNE和斯坦福的node2vec.上面其实已经提了下node2vec的精髓.
大家可以在最后的reference里面找对应论文来读,以下是我找到的中文笔记和代码实现.
中文笔记:
Node2vec
SDNE
SDNE应用于阿里凑单推荐系统
代码:
node2vec in python
node2vec in scala code
node2vec in c++ code
sdne非官方实现 python
图卷积网络的适用场景
- 自然语言处理
- 知识图谱
- 社交网络
- 图聚类分析
- 社群识别
- 推荐系统
基本只要你能构建一张图,并且认为图上的信息能帮助模型更好地决策,你就可以考虑GNN了.
比如利用知识图谱,预测实体之间是否会产生链接(Link Prediction).
比如Fraud detection里面,每个节点是一个商家,每一条线是商家之间的交易.你希望加入商家之间的交易信息作为特征,预测商家是否在洗钱.
比如推荐朋友时,每个节点是一个用户, 你希望根据用户John已有朋友圈,预测某个用户Alex是否可能是用户John的朋友.
应用的时候可以思考, 你是需要在node level, link level, 还是graph level建模.
Reference
- Thomas Kipf对GCN的介绍
- Semi-supervised Classification with GCN
- Representation Learning on Graphs: Methods and Applications - Stanford 2017
- Graph Representation Learning - Stanford CS224W slides - Fall 2019
- node2vec: Scalable feature learning for networks
- node2vec in python
- node2vec in scala code
- node2vec in c++ code
- Asymmetric Transitivity Preserving Graph Embedding - HOPE - KDD2016
- Structural Deep Network Embedding - SDNE
- DeepWalk: Online Learning of Social Representations
- Anonymous Walk Embeddings - ICML 2018


Comments