11 min to read
句子之间的连贯程度如何衡量?
Ways to analyze the local coherence of text

上篇讨论了全局连贯性.今天跟大家聊聊语篇局部连贯度分析~
局部连贯是指语篇的句子级别的连贯度,比如前后连接的句子对之间是否连贯.有三种分析局部连贯的角度, 我们将介绍每一个研究角度下的成果.
本文要点
如何解析句子间的连贯关系
这个角度的出发点是如果两个句子之间存在某种逻辑关系,那么这段话是连贯的.
理论框架
常用的理论框架是修辞结构理论(Rhetorical Structure Theory).接下来简称RST.
RST分析的最小单位是一对句子或一对词组,句子/词组称为基础语篇单位(Elementary Discourse Unit/EDU)或者语篇段(discourse segment).
RST定义的每一类关系中,都定义了一个核心角色与一个卫星角色.
核心(nucleus) 能够被独立理解,更接近作者的行文目的.
卫星(satellite) 的内容一般需要结合核心去理解. (好生动有没有!)
以下是一小部分RST定义的连贯关系:
- 起因Reason ——核心是一个行为动作,卫星是这个动作的起因
e.g. [Flora星期五没有来.]nucleus [因为她要去参加朋友的婚礼.]satellite - 详述Elaboration ——核心是一个状态,卫星是对这个状态的补充描述
e.g. [Phoebe来自曼哈顿.]nucleus[她住在中央公园的西边.]satellite - 论据Evidence ——核心表达了一个观点,卫星是支撑的论据
e.g. [今天下班肯定会塞车.]nucleus[今晚有周杰伦演唱会]satellite - 语源Attribution ——核心是一段话语,卫星指明了说话者是谁
e.g. [Frank跟我说]satellite[今天美术馆人会很少.]nucleus
e.g. [Analysts estimated]satellite[that sales at U.S. stores declined in the quarter]nucleus - List ——两个句子都是核心角色,关系是并列的
e.g.[他是班长.]nucleus[她是团支书.]nucleus
RST树干:

RST理论通过给一对对的EDU标注连贯关系,形成像这样解析全文的RST树:
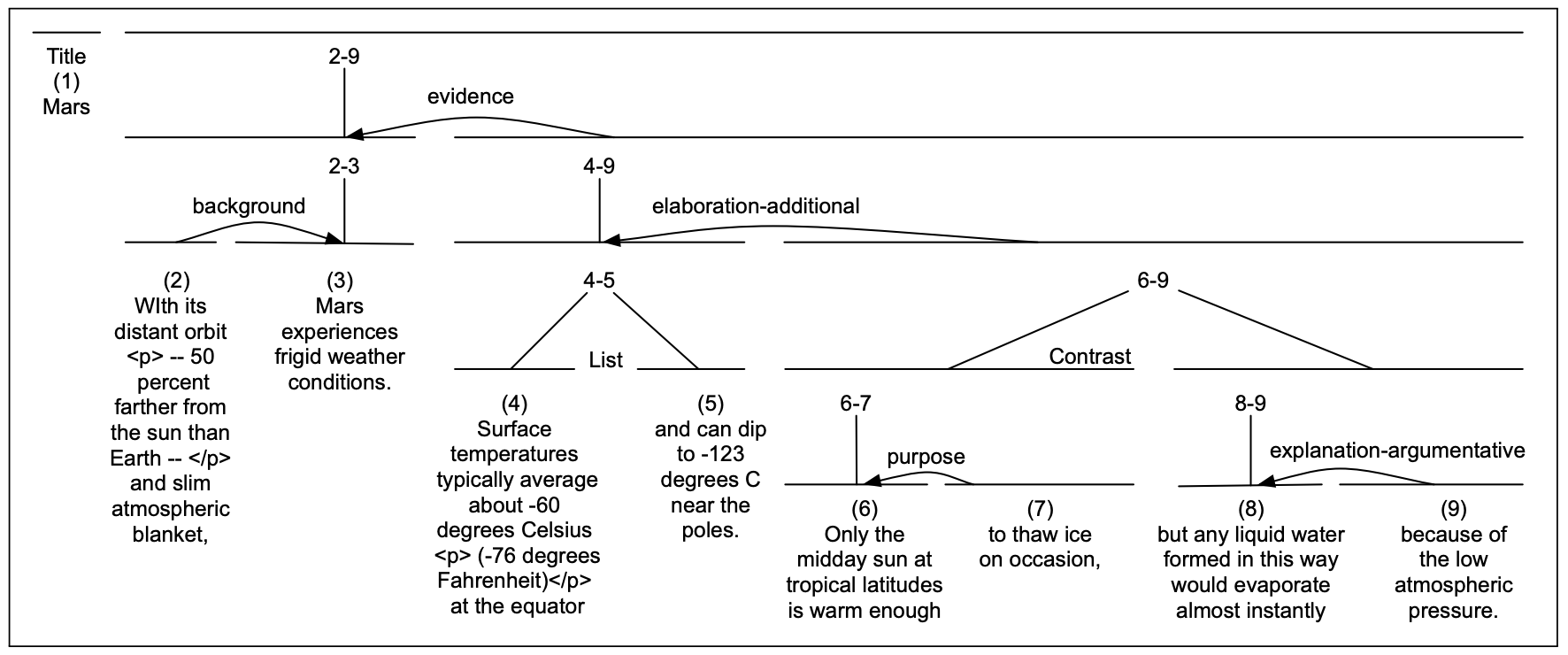
要注意到这种语篇级别的RST树的标注是很昂贵的,像PDTB这样的数据集就不包含树,只包含句子级别的关系标注.
所以也有只解析句子级别连贯度的解析器,这里简称为PDTB解析好了.
数据集
- Penn Discourse TreeBank/PDTB (最新2008)
包含18000个明确关系(explicit relation),16000个隐含关系(implicit relation)
只包含每一对span的关系(span-pair relation),不包含整个语篇级别的树.
打标注的人被要求做选择题,在一堆关联词里面选一个作为输入句子对的连接词,选择有: because, although, when, since, or as a result,然后这些关联词会与逻辑关系对应,比如because对应到因果关系. - RST Treebank (2002)
从the Penn Treebank数据集里面选了385个英文文本(347训练/38测试),以及它们的RST解析树 也就是会将标注整理为整个语篇层面的树状. - Chinese Discourse TreeBank(2014) 中文的数据集.
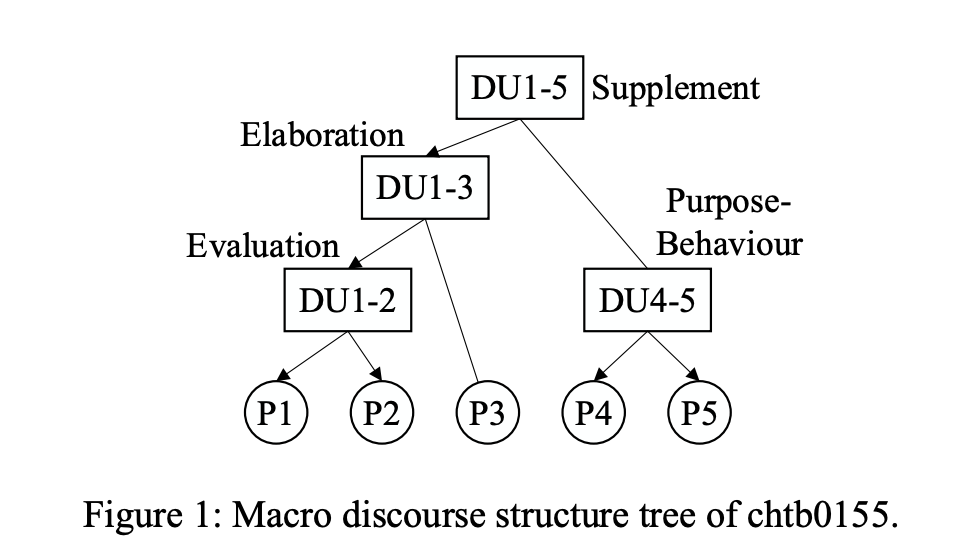
按照PDTB的风格给164个中文文档标注. 由于中文里面明确关联词的使用率比英语低,这个数据集直接给每一对语篇段打关系标注,有11种不同的标签. - MCDTB A Macro-Level Chinese Discourse TreeBank (2018)
中文的数据集.
考虑段落之间的关系, 有像RST树的语篇级别的标注.
解析树
如何语篇解析成RST树?
第一步:基础语篇单位切分(EDU segmentation)
——把文本切成小块小块,或者叫语篇切分(discourse segmentation)
第二步: 对EDU们做RST解析 (RST Parsing)
——从下往上合并EDU,自动生成一棵树
如何把文本切成小块
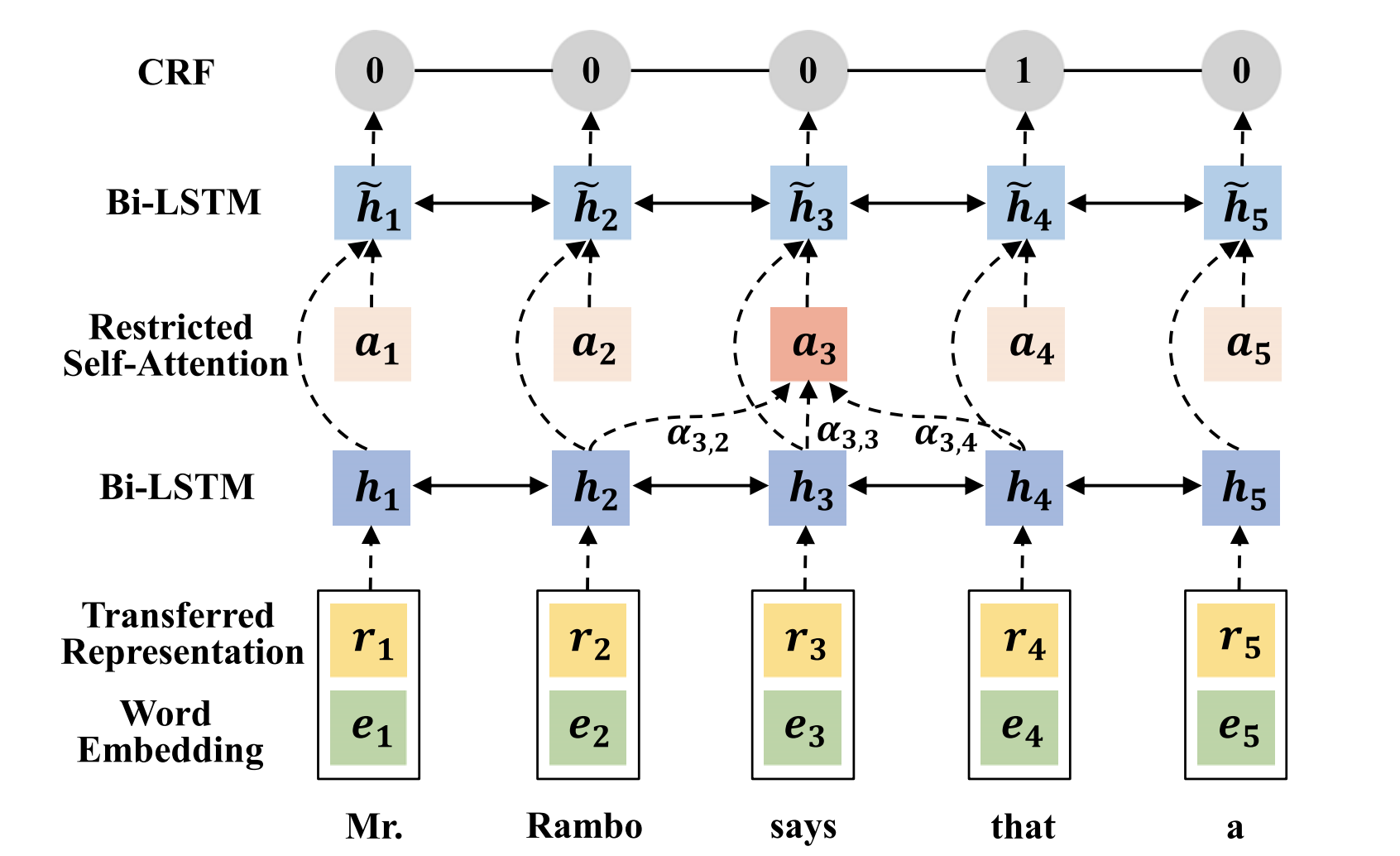
使用RST Discourse Treebank数据集,训练一个序列标注(sequential labelling)模型.被标注为1的位置表示从这里切断句子,分成前后两个EDU.
模型的设计就是典型序列标注任务的套路了: BiLSTM-CRF.
今天以一篇EMNLP 2018的论文为例,看看常用的模型结构.
 从下往上看:
从下往上看:
a1. 拿到词嵌入向量
先把词过ELMO,得到向量表示r1,再跟另外一个向量表示e1粘起来,得到输入(黄色与绿色)
- why? 由于RST的数据集很小,从零开始训练显然效果会差,于是用了预训练的ELMO.
a2. 得到词语上下文信息
过个BiLSTM,然后把每个time step得到的两个hidden state向量粘起来
a3. 允许模型重视上下文中的特定位置
在一个限定长度的窗口里面算注意力an,也黏到bi-LSTM的输出上,输出
\(\tilde{h_{n}}\)
a4. 判断
最后每个位置的标签由CRF模型决定,求的是序列走到这一步时所有可能标签的条件概率
看到这里你肯定猜到了,没错又有人把词嵌入从ELMO换成了BERT然后刷了一下准确率…
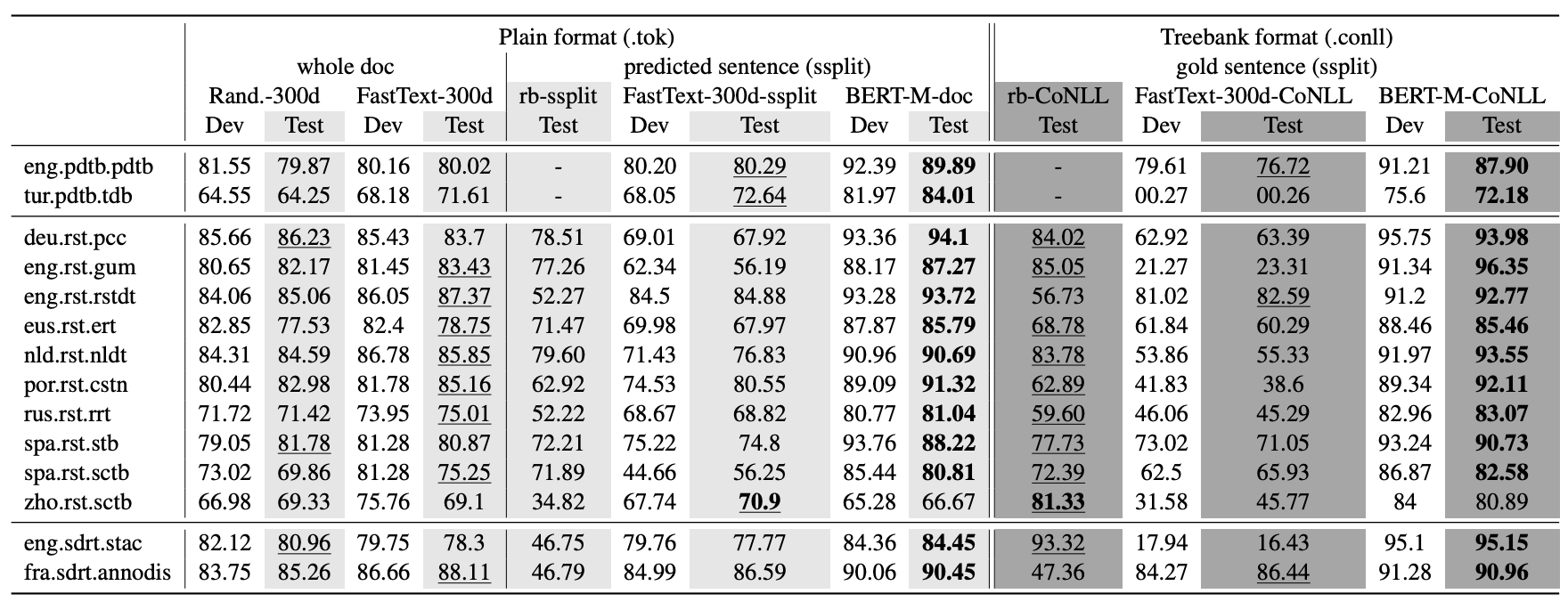 论文传送门
论文传送门
最右边一列就是BERT,BERT在中文数据集上表现平平,在其他语言上BERT的表现很好.
论文原话:BERT contextual embeddings beats all other systems on all datasets – except the Chinese RST treebank –, often by a large margin.
如何做修辞结构解析
理论框架
从1999年以来, RST解析都是用shift-reduce parsing模型框架
Shift-reduce Parser的基本设定
- 需要一个队列Queue与一个栈Stack
- shift动作: 把队列最前面的EDU的放进栈里面
- reduce(l, d)动作: 把栈最上面的两个成员merge成一个成员
- l 指的是连贯关系的标签,d指的是卫星-核心的方向(nuclearity direction), d ∈ {NN,NS,SN}
- NN = 两个EDU都是核心(关系箭头是双向的/无向的)
- NS = 左边的EDU是核心 右边的EDU是卫星(关系箭头指向左边的EDU)
- SN = 左边的EDU是卫星 右边的EDU是核心(关系箭头指向右边的EDU)
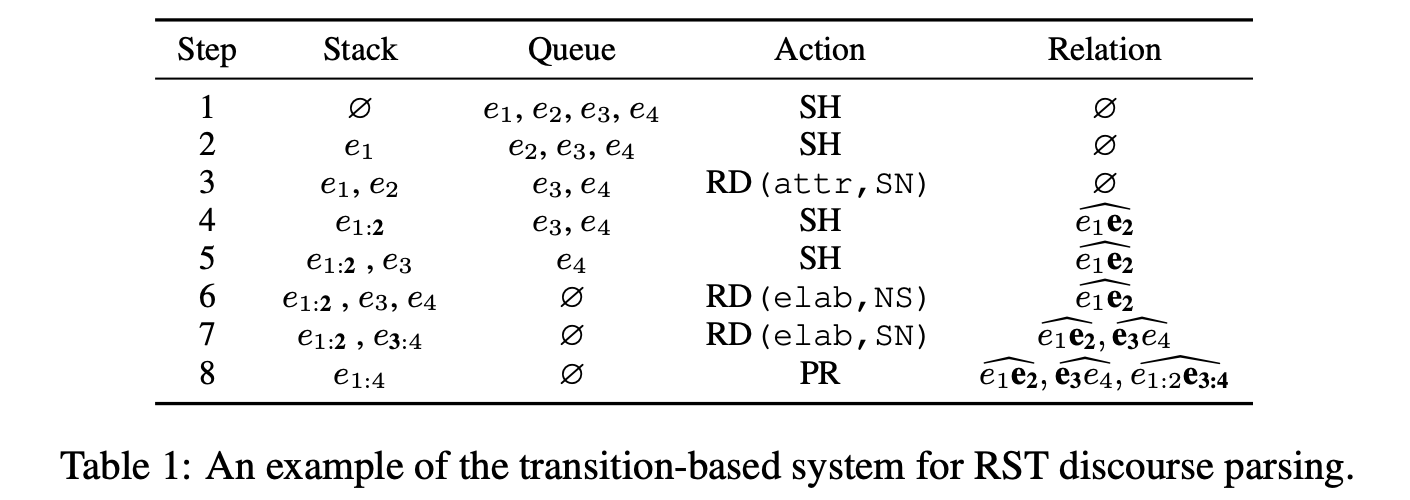
- 栗子
假设我们现在目标是把如下的RST树建起来: 图片来源
图片来源
可以看到一共有4句话:
e1, e2, e3, e4,
两种连贯关系:attribution和elaboration
需要对队列里面的EDU做如下操作, bottom-up地把树建出来:
 图片来源
图片来源
解析器每一步能做的就是从两个Action中选一个做:SH - shift或者RD - reduce
基本框架知道了,那么模型怎么知道选哪个action?
之前的parser是靠一些设定的规则选择shift和reduce.
近几年出现了神经网络风格的RST解析器,今天以论文Transition-based Neural RST Parsing with Implicit Syntax Features为例, 看如何先得到句子向量表示,然后有监督地训练序列分类模型选择action.
- 如何得到句嵌入向量——建一个编码器(encoder)
- 假设你现在有一段文本,有词语 w1, w2, …, wt
- 它先用常规操作得到每个词的向量表示(比如字母级别嵌入模型、词嵌入模型、好几个模型粘起来,etc);
- 过Bi-LSTM得到 h1, h2, …, ht ;
- 过average pooling得到这段文本不同长度的表示x1e, x2e, …, xne ;
-
\(x^{e} = \frac{1}{t-s+1}\sum_{k=s}^{t} h_{k}^{w}\)
- 然后这些不同长度的表示x1e, x2e, …, xne 过第二层Bi-LSTM得到最终的这段文本的表示 h1e, h2e, …, hne .
- 如何选择action——前馈神经网络
- 分类器是一个简单的前馈神经网络.网络的输入是栈最上面的三个成员 s0,s1,s2的表示向量 以及 队列下一个的成员的表示向量
-
\(o = W(h_{s0}^{t},h_{s1}^{t},h_{s2}^{t},h_{q0}^{e} )\)
- 注意栈里面的成员有可能是带树叶的树干,所以每个成员的表示向量是成员那根树枝里面所有EDU的表示向量average pooling之后的结果,队列q0里面的成员因为一定是单个EDU,所以直接用上面encoder的输出就好.
- 如何训练——需要把树扁平成操作
- 首先要把正确答案的RST树转化成一系列的shift,reduce操作.
- 然后既然是分类器,就把输出的action数值softmax一下转化成操作的概率分布paction,使用交叉熵作为损失函数.
- 如何评价——RST-Pareval metrics
- 一般会把正确答案的RST树转化成向右展开的二叉树,然后算四样东西: trees with no labels (S for Span), labeled with nuclei (N), with relations (R), or both (F for Full), 对这四个评价指标都算micro-averaged F1.
只解析句子对
通常被称为浅层语篇解析(shallow discourse parsing),因为任务只涉及span对子之间的联系.而不是像RST解析一样,目标是得到语篇的一整颗树.
使用PDTB这种不包含树结构标注的数据集.
四种不同的子任务
- 区分有连贯作用的关联词与没有连贯作用的词
e.g1. Selling picked up as previous buyers bailed out of their positions and aggressive short sellers—anticipating further declines—moved in.
and这个关联词有连贯作用, 它用elaboration的关系连接了两个句子
e.g2. My favorite colors are blue and green
and这个词在这只是两个词的连接, 没有连贯作用
以前这个任务是语言学的路子做,今年有了序列分类的做法: 标签是IOB类标签,用CRF+Bi-LSTM - 找到关联词连接的两个句子(span)
还是序列标注模型 - 给任务2中找到的关联词联系起来的两个句子,打关系标签(Coherence Relation Assignment)
很难的一个任务,已有的方法是使用提示词/提示短语(cue phrase):
先将句子中的提示词找到; 将文本做语篇切分,得到一个个EDU; 对于相邻的两个EDU,对它俩的关系进行分类 - 给任意一对前后句子打关系标签(Implicit Relation Prediction)
这个子领域目前的SOTA怎么做的呢?简单而有效的一个模型:
用BERT得到两个span的表示,取token对应的timestep的hidden state, 过一层tanh,再过一层softmax,得到sense分类的概率分布.
如何追踪语篇当下的核心实体
这个角度的出发点是,如果一些句子在讨论同一个实体,那么这些句子组成的语篇是连贯的.
- salience 显著性,就是一个实体对于受众来说,清楚明了的程度
- Centering Theory 一种使用CONTINUE和SHIFT描述中心实体变化的理论
- Entity Grid 一种追踪文本中实体的矩阵,每一列是一种实体,每一行代表文本中的一句话
Centering Theory
认为一个语篇的任意一个位置都有一个单独的实体是显著的(salient),被作为中心(center).
如果邻近的句子们的center是同一个实体,那么它们是CONTINUE的.
不然它们就是在不同的center之间来回SHIFT.
-
栗子
文本1:
a. John went to his favorite music store to buy a piano.
b. He had frequented the store for many years.
c. He was excited that he could finally buy a piano.
d. He arrived just as the store was closing for the day.
文本2:
a. John went to his favorite music store to buy a piano.
b. It was a store John had frequented for many years.
c. He was excited that he could finally buy a piano.
d. It was closing just as John arrived.
明明想传达的信息是一样的,哪个文本更连贯?
Centering Theory会认为第一个更连贯. 因为第一个文本中的句子的center一直是John. 第二个文本中center从John换成Store又换成John又换成Store. - Center分为语段潜在中心 (forward-looking center C_f) 和语段现实中心(backward-looking center C_b)两种.
- 假如一个语篇有 U1, U2,…, Un 共n句话,
- C_f(U_i) 就是(向后预测)第i句话中可能的中心实体的集合
集合里面所有成员按照如下规则排序: cmu的相关PPT
Subj > ExistPredNom > Obj > IndObj-Obl > DemAdvPP
里面排序最高的称为C_p (Preferred Center) - C_b(U_i) 就是(回头看)第i句话实际的那个中心实体
- 预测的某实体和实际的中心实体一样的话,我们就说这个实体被实现了(realize).
- 通过定义C_f和C_b的关系,定义了CONTINUE和SHIFT
 前后句子的center是同一个实体,且符合预期 -> Continue
前后句子的center是同一个实体,且符合预期 -> Continue
后一个句子的center变了,是预料之中的转折 -> Smooth-Shift
后一个句子还在说同一个实体,可是预期应该说另一个实体了 -> Retain
后一个句子的center变了,而且是预料不到的转折 -> Rough-Shift- 栗子
U1 小悦去她最喜欢的乐器行买钢琴.
U2 她很激动终于能买一架钢琴了.
U3 她在乐器行正要关门的时候到了店里.
U4 它在小悦到的那会儿刚关门.
~~
C_f(U1) = {小悦, 乐器行, 钢琴}
C_p(U1) = 小悦
C_b(U1) = 未知
~~
C_f(U2) = {小悦, 钢琴}
C_p(U2) = 小悦
C_b(U2) = 小悦
因为(C_p(U2)=C_b(U2) 且 C_b(U1) = 未知
所以判断:CONTINUE
~~
C_f(U3) = {小悦,乐器行}
C_p(U3) = 小悦
C_b(U3) = 小悦
因为(C_p(U3)=C_b(U3) 且 C_b(U3) = C_b(U2)
所以判断:CONTINUE
~~
C_f(U4) = {乐器行,小悦}
C_p(U4) = 乐器行
C_b(U4) = 乐器行
因为(C_p(U4) =C_b(U4)) 且 C_b(U4) != C_b(U3)
所以判断: SMOOTH-SHIFT
- 栗子
- 两条规则
- 第一条规则 如果前一句话任何一个预测中心实体,在后一句话中被用代词实现了的话, 那后一句话的实际中心实体也肯定是被代词实现的.
- 第二条规则
连贯性:Continue > Retain > Smooth-shift > Rough-shift
这条规则决定了,当有多个可能的解析方式(C_b不能确定是C_f中的哪一个)时,应当选择能得到连贯性更强结果的解析方式
显然Centering Theory这种判断方式的缺点是,规则很死很僵硬,人并不会这样去得到一个文本是否连贯.
Entity grid
用机器学习推测使语篇更连贯的表达套路.听上去就比上面原始的rule-base风格好很多有没有.
使用一个二维矩阵,每一行是一个句子,每一列是一个实体,每一个格子代表某实体是否出现在某句子中,以及它在句子中的语法角色(grammatical role): 主语subject (S), 谓语object (O), 既不是主语也不是谓语neither (X), 实体没出现absent (–).
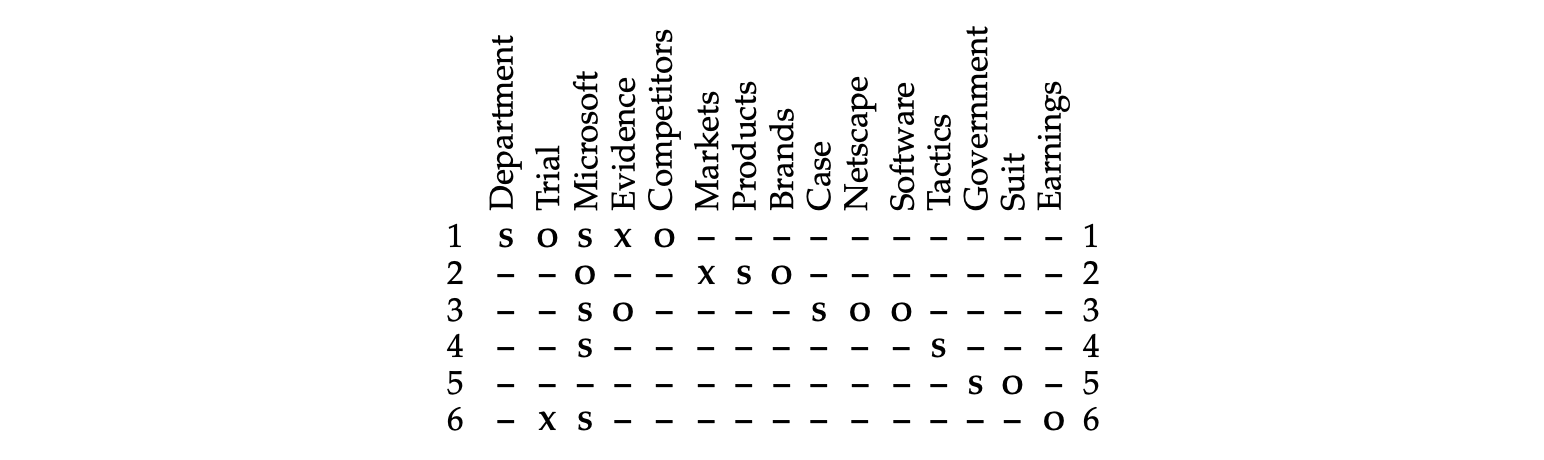
上图为实例文本d1 的Entity grid
矩阵中密集的列表示该实体被频繁提及,稀疏的列表示实体鲜少被提及.
如何得到这个Entity grid矩阵?
计算这个矩阵需要做命名实体识别任务NER,把句子中的实体都找到,然后还需要做共指消解(coreference resolution)任务,把取出来的实体表达聚类到现实实体上.
Entity grid如何利用这个矩阵衡量语篇的连贯性呢?
计算局部实体转移矩阵(local entity transition).也就是单独看每一列,相邻格子之间值的变化.
打个比方,长度为2的transition,因为每个格子可能的值有4个,就有4^2 = 16种可能.
实体转移矩阵里每个格子就是一种transition在Entity Grid中出现的频率.
比如看上面的文本d1 Entity grid例子,有75个格子
S->S的频率 1/75 = 0.013
S -> -的频率 6/75 = 0.08

模型
- 训练一个文本分类器,用这些transition和他们的概率将文本分类为连贯的或者不连贯的,或者给出文本的连贯性打分.但是这种有监督地方式需要人工标签啊,很贵.
- 可以选择做 自监督(self-supervision):
让训练分类器区分 原始文本和句子顺序被调整之后的文本.这样就可以用文本本身建数据集,不需要人工标注.
如何使用纯神经网络给语篇的连贯度打分
- 最贵最好的——人工标注文本连贯性,然后训练分类器给文本打分
- 没那么贵的——自监督学习,将原始文本与打乱句子顺序的文本搭配起来组成训练集,成功的连贯性打分模型应该总选原始文本.
三种自监督学习的任务,难度递增
- 随机排列(Sentence Order Discrimination)
将原始文本中的句子顺序自由排列形成假文本, 将(原始文本,假文本)对子作为模型输入,如果模型给原始文本的打分比假文本的打分高,就算它对. - 随机加入(Sentence Insertion)
假设原始文本有N句话,将其中一句话s拿出来,放到剩下的N-1个位置上去,形成N-1个假文本.
将N-1个假文本与原始文本放在一起,让模型判断N个文本中的哪一个是原始文本.
因为真假文本之间只有一句话的差别,这个任务会比(1)更难. - 重新排序(Sentence Order Reconstruction)
一个超难的任务,先把原始文本的顺序打乱,训练模型把它们顺序重新排好.
自监督实现打分模型
以2019年的Local Coherence Discriminator(LCD)模型为例:
模型需要区别 原文中真正前后相邻的句子对(si, si+1) 和 随机与前边句子配对所生成的句子对(si, s’)
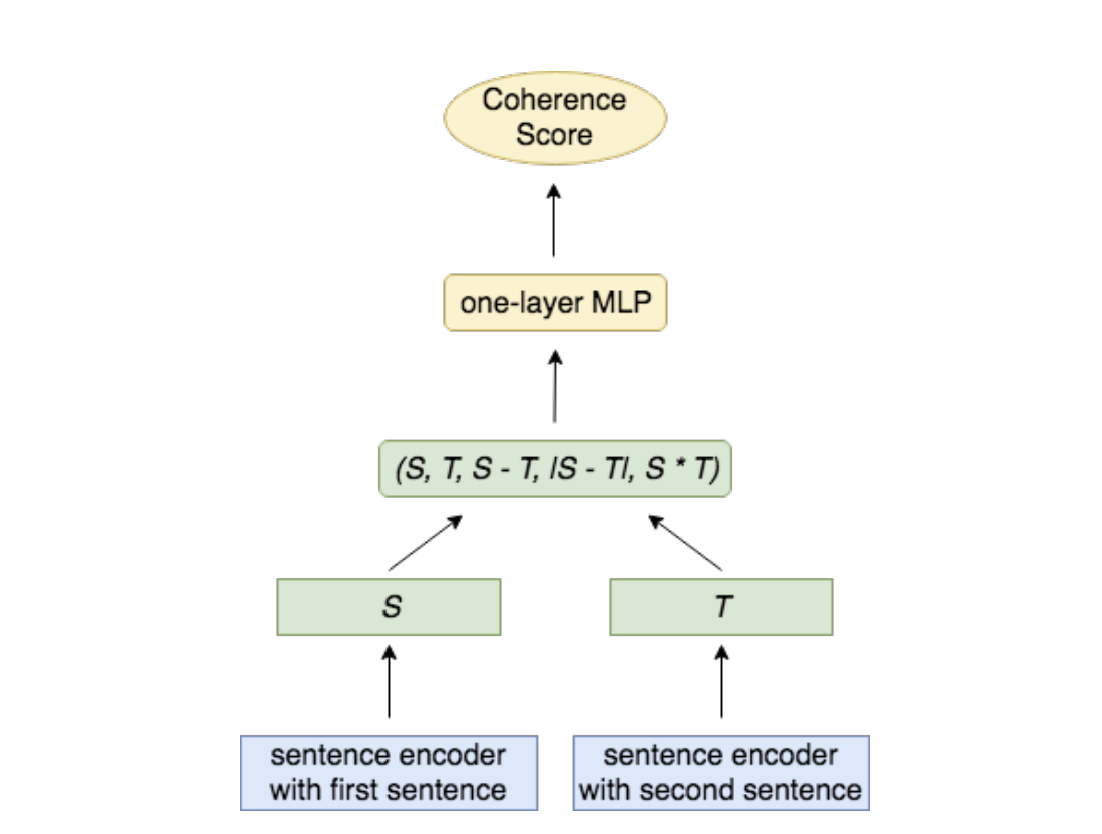 先学出来一个句嵌入模型,能将句子转化成表示向量,然后将相邻句子表示成向量之后,再用一个简单的前馈神经网络得到最后分类(是否是原始文本,即是否连贯).
先学出来一个句嵌入模型,能将句子转化成表示向量,然后将相邻句子表示成向量之后,再用一个简单的前馈神经网络得到最后分类(是否是原始文本,即是否连贯).
假设整篇文本的连贯度等于文本中所有前后相邻的两个句子的连贯度的均值.
假设前一句话的句嵌入向量是S,后一句话的句嵌入向量是T.
(这边使用的句嵌入模型不限,可以是任何预训练的生成式模型的编码器部分,或者Glove, InferSent之类)
输入的特征由4个东西组成:
S, T, S - T, |S - T|, S·T
分类使用的就是个简单的Multi-layer Perceptron
一个强力的句嵌入模型被这篇论文证明是的确可以提高任务的准确率的,比如随机排列任务和随机加入任务的分类准确率都会变好.
论文原话 we do benefit from strong pre-trained encoders
衡量困惑度(Perplexity)的新指标
论文还提出可以训练一个预测下一个词的RNN语言模型, 以两种方式计算一个句子s的log likelihood:
- 包含上文计算条件log likelihood
- 不包含上文计算marginal log likelihood
然后1,2做差,得到上文对预测句子s的影响力度,也可以看做是上文与这个句子之间的连贯性强度.
总结
本文结合最新的论文, 介绍了局部连贯度的三个研究角度的理论和模型.
理论有修辞结构理论(Rhetorical Structure Theory)和中心理论(Centering Theory), 研究框架包括RST解析, PDTB解析, 基于Entity Grid分类,基于句嵌入向量用MLP分类.
由于标注数据昂贵,可以使用自监督方式建立数据集训练.
Reference
- Speech and Language Processing
- Toward fast and accurate neural discourse segmentation. In EMNLP 2018
- ToNy: Contextual embeddings for accurate multilingual discourse segmentation of full documents. In ACL 2019
- Transition-based Neural RST Parsing with Implicit Syntax Features. In ACL 2018
- CMU slides: NLP - Discourse, Entity Linking, and Pragmatcs
- DisSent: Learning Sentence Representations from Explicit Discourse Relations. In ACL 2019
- CMU slides for 11-711 Algorithms for NLP: Computational Discourse
- A Cross-Domain Transferable Neural Coherence Model. In ACL 2019


Comments