3 min to read
电脑也能写出连贯的文章吗?
A High-level Introduction to Discourse Coherence

生成式模型大行其道的今天,我们已经知道电脑能够自己写文章了.
但是他们文章的连贯度如何呢?
本文是语篇连贯度分析专题的上篇. 下篇专门讲局部连贯度分析的不同模型.
本文要点
简单介绍语篇连贯分析
Q1: 我们为什么在乎文本的连贯度高不高?
A1: 任何需要保证文本输出质量的NLP产品都需要语篇连贯度分析. 比如信息抽取、自动摘要、机器翻译.
Q2: 什么是连贯(coherence)?
A2: 连贯是一种句子之间的关系,定义了逻辑顺畅的语篇与随机排列的句子们之间的区别.
Q3: 可以从哪些角度一个文本的连贯度?
A3: 分为局部连贯(local coherence)以及全局连贯(global coherence).
局部连贯是指语篇中连续N句话之间的关系,比如前后连接的句子对(span)之间的连贯关系;
全局连贯是指站在段落乃至全文的高度,看语篇的行文结构对全文连贯度的影响.
Q4: 什么是语篇连贯度分析任务?
A4: 有很多方向,比如自动的对语篇进行解析,进而得到全文逻辑结构的图形表示;训练模型自动衡量文本的连贯度并打分.
如何分析语篇的局部连贯度
三种分析局部连贯的角度
一段话之所以连贯,可能是因为前后句子之间有逻辑关系,也可能是因为它们在讨论同一个现实世界的实体,还有可能是因为它们在讨论一个核心的话题.
- 句子之间存在连贯关系(Coherence Relations)
句子之间可以存在各种各样的连贯逻辑关系.
有RST树和PDTB两种不同风格的框架来句子之间不同的逻辑关系,第二部分会细讲. - 存在Entity-based Coherence
句子们在讨论同一个中心的实体(称之为Center).
这个研究角度会追踪一个语篇里面,目前被讨论的实体是什么,如果实体变来变去,显然这个语篇就不是一个很连贯的语篇. - 存在Topical Coherence
句子们在讨论同一个话题,也就是使用同一个semantic field里面的词语 e.g. Before winter I built a chimney, and shingled the sides of my house… I have thus a tight shingled and plastered house… with a garret and a closet, a large window on each side.
下篇专门讲局部连贯度分析的Post里面会包括:
- 如何解析句子间的连贯关系(coherence relation)
- 如何追踪语篇当下的核心实体
- 如何使用纯神经网络给语篇的连贯度打分
如何分析不同文体的全局连贯度
全局连贯是指站在全文的高度,看语篇的行文结构对全文连贯度的影响.
起源可以从Propp’s model开始说:
它将故事的常见角色总结了出来,称为dramatis personae. 比如主人公(Hero),反派(Villian),Donor,Helper等.
这里简单带过对两种不同文体的全局连贯度研究:议论文和科研论文.
如何研究议论文的全局连贯度
- argument mining 一个任务,让计算机自动研究议论文
根据亚里士多德的理论,要论证一个观点可以通过三种修辞形式:
- pathos 感情上打动受众
- ethos 从受众的个性出发
- logos 逻辑上说服受众.
数据集
现代模型主要研究用逻辑论证(logos)的议论文,一般训练集是标注好论点claim,论据premise的议论文.有时候还会包括论证关系(argumentative relation), 比如SUPPORT或者ATTACK.
示例议论文数据:
“(1) Museums and art galleries provide a better understanding about arts than Internet.
(2) In most museums and art galleries, detailed descriptions in terms of the background, history and author are provided.
(3) Seeing an artwork online is not the same as watching it with our own eyes, as
(4) the picture online does not show the texture or three-dimensional structure of the art, which is important to study.”
第1句话是论点
第2,3句话是支持论点的论据
第4句话是支持3的论据
所以表示成函数就是SUPPORT(2, 1), SUPPORT(3, 1), SUPPORT(4, 3)
一篇议论文可以表示为下图
(感觉高中时候的同学要是有了能自己写议论文的算法,好多人都不怕写作文了哈哈)
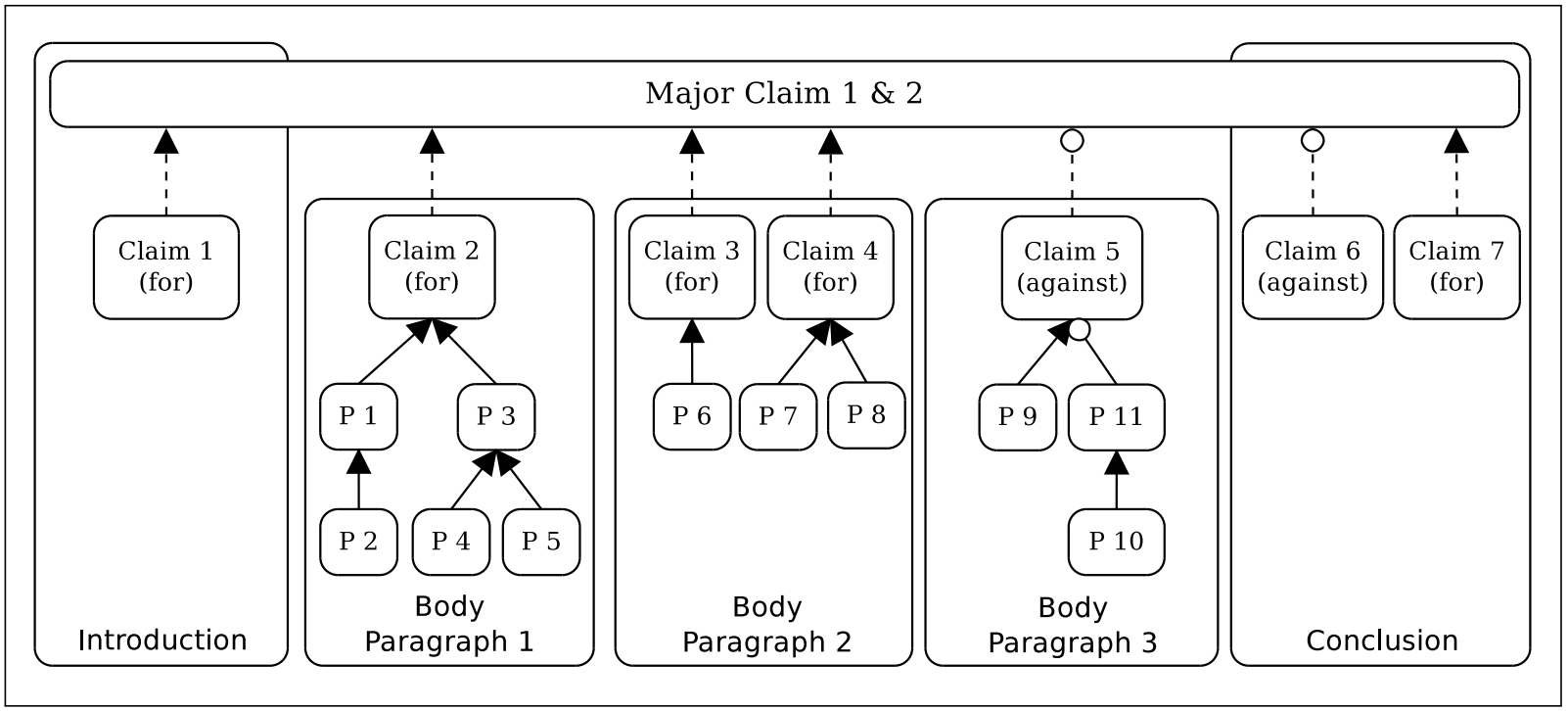
图片来自论文
尖头箭头表示SUPPORT,圆头箭头表示ATTACK.
有趣的是,可以注意到Claim5表示了反证法
 先提出反对的观点Claim5, 用Premise 9支持这个观点, 然后用Premise 11和Premise 10攻击这个观点,论证这个观点是错误的.
先提出反对的观点Claim5, 用Premise 9支持这个观点, 然后用Premise 11和Premise 10攻击这个观点,论证这个观点是错误的.
分析议论文结构的模型
一般是两个文本分类器,一个负责区分论点、论据和非议论文本(non-argumentation).
另一个负责区分两句话之间的关系是SUPPORT, ATTACK, 还是都没有.
另外的研究方向
- 探索议论文除了SUPPORT和ATTACK之外更复杂的论证关系
- 研究不同的语篇结构对文章说服力强弱的影响
- 根据社会学角度设计出的特征,判断社交平台上谁是意见领袖,谁是被影响的受众
如何研究科研论文的全局连贯度
- argumentative zoning 是指对科研论文修辞的研究
科研论文的结构一般包括目的、方法、结果、与已有研究的比较等.
数据集
论文中的每个句子被分为15种类别的标注.
比如:
目的AIM —— 句子表明了研究目的
新方法OWN_METHOD
新结果OWN_RESULT
使用USE —— 句子表明了研究中使用了什么工具/方法
缺陷GAP_WEAK —— 句子指出了本领域未被解决的问题,已有方案的不足
支持SUPPORT —— 句子提供了已有研究对本研究的支持
矛盾ANTISUPPORT —— 句子提出了对某已有结论的挑战
整个表如下:
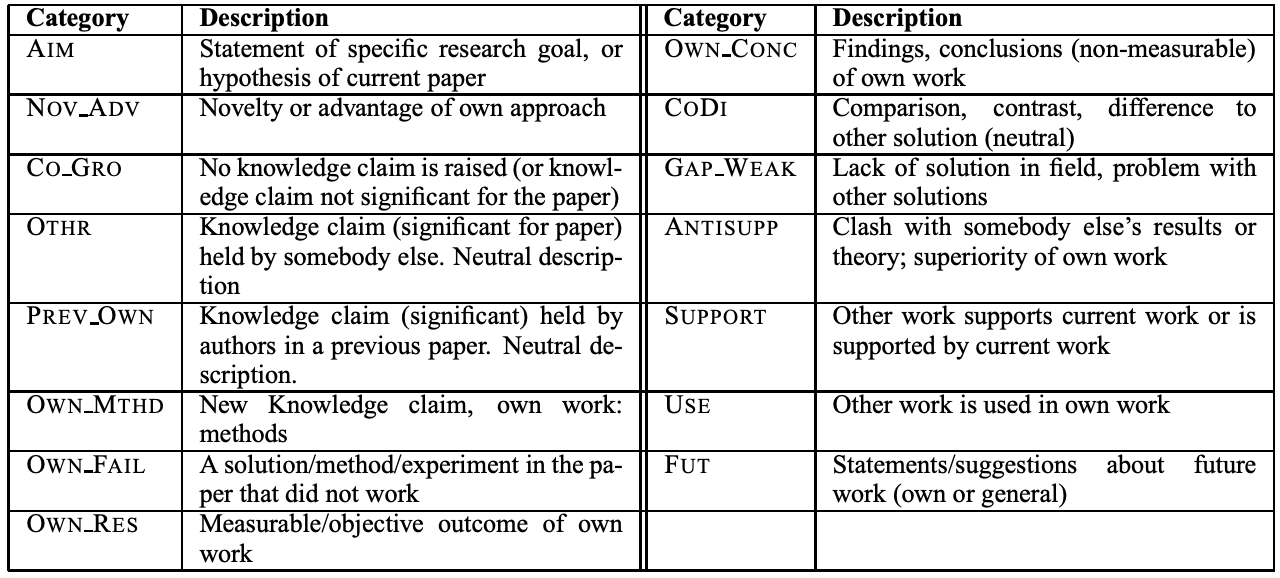
图片来自论文
总结
本文作为语篇连贯分析的上篇,介绍了这个领域的基本概念, 研究框架, 数据集和模型. 局部连贯度可以通过研究三条路研究:判断连贯关系,追踪讨论实体,以话题为中心.
不同问题的全局连贯度不同,介绍了议论文文体和科研论文文体.
下一篇我们将聚焦到语篇的局部连贯度分析,具体看每个研究角度都有什么理论框架和模型.


Comments